
IT之家 4 月 14 日消息,IT之家從騰訊官方獲悉,騰訊云發布了新一代 HCC 高性能計算集群,采用最新一代星星海自研服務器,搭載英偉達 H800 Tensor Core GPU。
騰訊官方稱,該集群基于自研網絡、存儲架構,帶來 3.2T 超高互聯帶寬、TB 級吞吐能力和千萬級 IOPS。實測結果顯示,新一代集群算力性能較前代提升 3 倍。
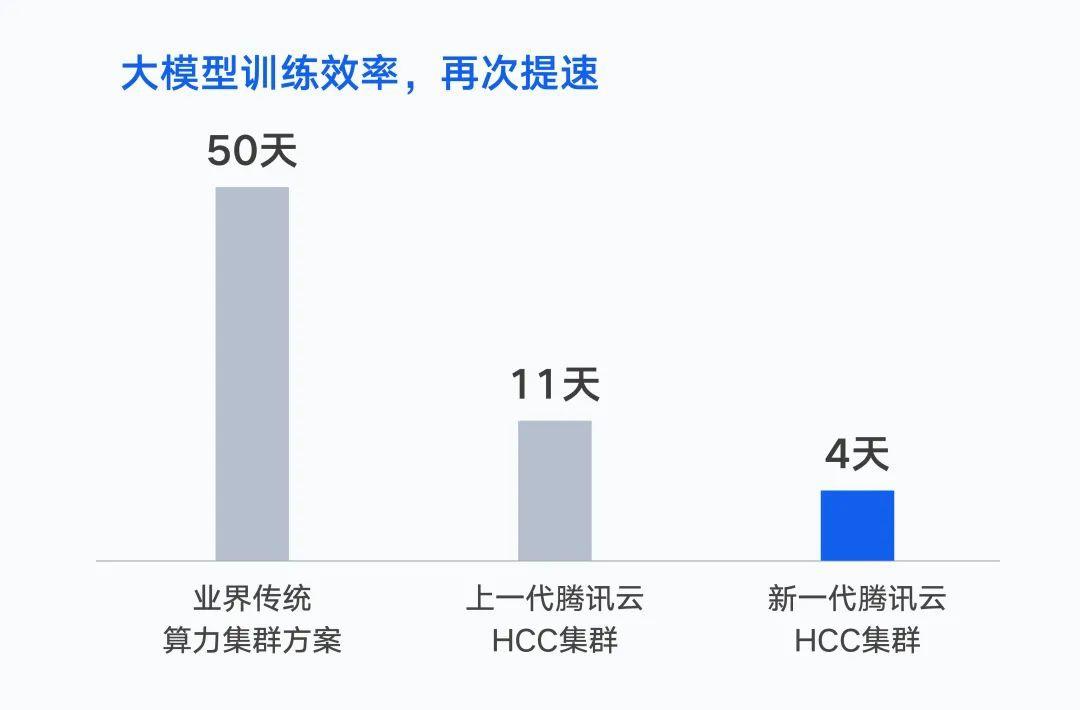
去年 10 月,騰訊完成首個萬億參數的 AI 大模型 —— 混元 NLP 大模型訓練。在同等數據集下,將訓練時間由 50 天縮短到 11 天。如果基于新一代集群,訓練時間將進一步縮短至 4 天。
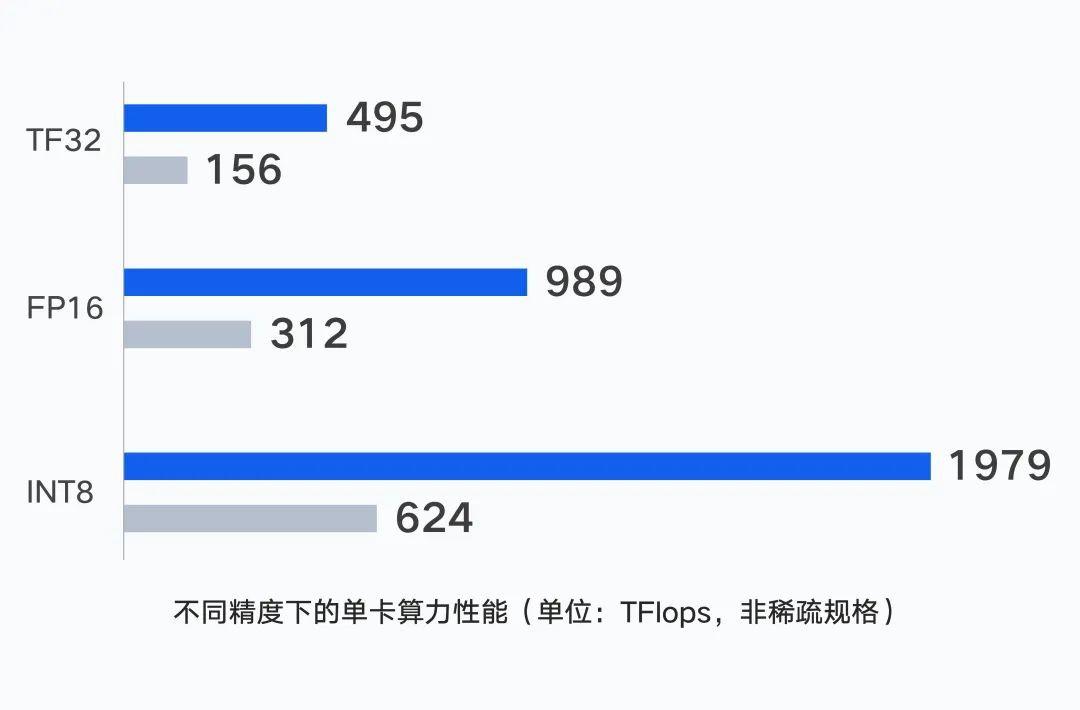
計算層面,服務器單機性能是集群算力的基礎,騰訊云新一代集群的單 GPU 卡在不同精度下,支持輸出最高 1979 TFlops 的算力。
針對大模型場景,星星海自研服務器采用 6U 超高密度設計,相較行業可支持的上架密度提高 30%;利用并行計算理念,通過 CPU 和 GPU 節點的一體化設計,將單點算力性能提升至更高。
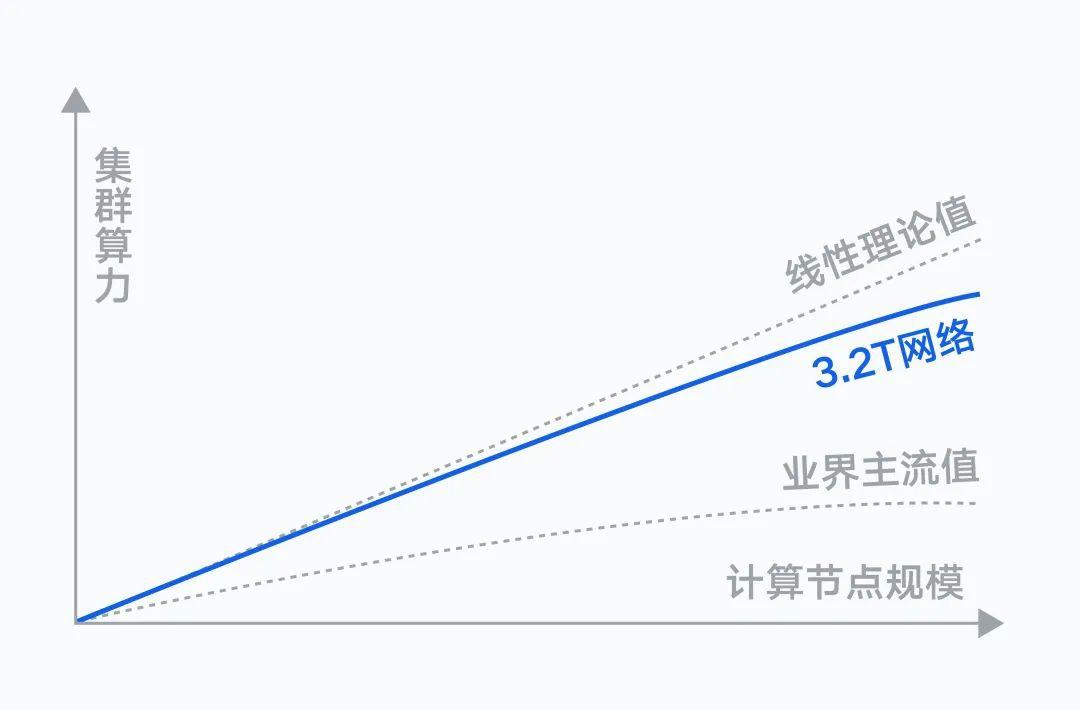
網絡層面,計算節點間,存在著海量的數據交互需求。隨著集群規模擴大,通信性能會直接影響訓練效率,需要實現網絡和計算節點的最大協同。
騰訊自研的星脈高性能計算網絡,號稱具備業界最高的 3.2T RDMA 通信帶寬。實測結果顯示,搭載同等數量的 GPU,3.2T 星脈網絡相較 1.6T 網絡,集群整體算力提升 20%。
同時,騰訊自研的高性能集合通信庫 TCCL,融入定制設計的解決方案。相對業界開源集合通信庫,為大模型訓練優化 40% 負載性能,消除多個網絡原因導致的訓練中斷問題。
存儲層面,大模型訓練中,大量計算節點會同時讀取一批數據集,需要盡可能縮短數據加載時長,避免計算節點產生等待。
騰訊云自研的存儲架構,具備 TB 級吞吐能力和千萬級 IOPS,支持不同場景下對存儲的需求。COS+GooseFS 對象存儲方案和 CFS Turbo 高性能文件存儲方案,充分滿足大模型場景下高性能、大吞吐和海量存儲要求。

此外,新一代集群集成了騰訊云自研的 TACO 訓練加速引擎,對網絡協議、通信策略、AI 框架、模型編譯進行大量系統級優化,大幅節約訓練調優和算力成本。
騰訊混元大模型背后的訓練框架 AngelPTM,也已通過騰訊云 TACO 提供服務,幫助企業加速大模型落地。
通過騰訊云 TI 平臺的大模型能力和工具箱,企業可結合產業場景數據進行精調訓練,提升生產效率、快速創建和部署 AI 應用。
依托分布式云原生的治理能力,騰訊云智算平臺提供 16 EFLOPS 的浮點算力。
