
近日,Meta 在 GitHub 上開源了一款全新的 AI 語言模型—— Massively Multilingual Speech ( MMS,大規(guī)模多語種語音) ,它與 ChatGPT 有著很大的不同,這款新的語言模型可以識別 4000 多種口語并生成 1100 多種語音(文本到語音)。發(fā)布短短幾天,該項目已經(jīng)在 GitHub 庫收獲了 25.4k Star,F(xiàn)ork 數(shù)量高達 5.7k。
論文地址:
https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
博客地址:
https://ai.facebook.com/blog/multilingual-model-speech-recognition/
代碼/模型:
https://github.com/facebookresearch/fairseq/tree/main/examples/mms
Meta 開源能識別 4000 多種語言的語音大模型
與大多數(shù)已公開發(fā)布的 AI 項目一樣,Meta這次也毫無意外地將 MMS 項目開源出來,希望保護語言多樣性并鼓勵研究人員在此基礎(chǔ)之上構(gòu)建其他成果。Meta 公司寫道,“我們公開分享這套模型和相關(guān)代碼,以便研究領(lǐng)域的其他參與者能在我們的工作基礎(chǔ)上進行構(gòu)建。通過這項工作,我們希望為保護令人驚嘆全球語言多樣性做出一點貢獻。”
語音識別和文本轉(zhuǎn)語音模型往往需要使用數(shù)千小時的音頻素材進行訓(xùn)練,同時附帶轉(zhuǎn)錄標(biāo)簽。(標(biāo)簽對機器學(xué)習(xí)至關(guān)重要,使得算法能夠正確分類并“理解”數(shù)據(jù)。)但對于那些在工業(yè)化國家并未廣泛使用的語言——其中許多語言在未來幾十年內(nèi)甚至有消失的風(fēng)險——Meta 提醒稱“根本就不存在這樣的數(shù)據(jù)”。
Meta AI 團隊稱,MMS項目最大的一個難點在于很多語言數(shù)據(jù)是缺失的。Meta AI 團隊通過結(jié)合 wav2vec 2.0(該公司的“自監(jiān)督語音表示學(xué)習(xí)”模型)和一個新數(shù)據(jù)集來克服其中一些挑戰(zhàn)。其中一些語言,例如 Tatuyo 語言,只有幾百人使用,而且對于其中的大多數(shù)語言,之前不存在語音技術(shù)。
Meta表示:“收集數(shù)千種語言的音頻數(shù)據(jù)是我們的第一個挑戰(zhàn),因為現(xiàn)有最大的語音數(shù)據(jù)集最多涵蓋 100 種語言。為了克服它,我們求助于圣經(jīng)等宗教文本,這些文本已被翻譯成多種不同的語言,并且其翻譯已被廣泛研究用于基于文本的語言翻譯研究。這些翻譯有公開的錄音,記錄了人們用不同語言閱讀這些文本的情況。作為該項目的一部分,我們創(chuàng)建了 1100 多種語言的新約讀物數(shù)據(jù)集,每種語言平均提供 32 小時的數(shù)據(jù)”。
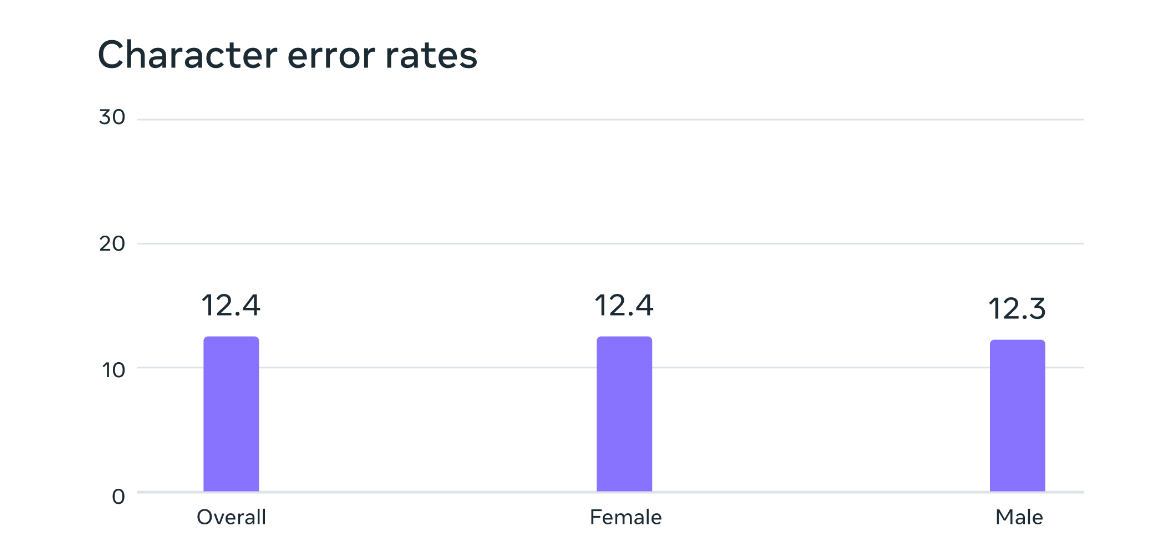
潛在的性別偏見分析。在 FLEURS 基準(zhǔn)測試中,基于大規(guī)模多語言語音數(shù)據(jù)訓(xùn)練的自動語音識別模型對于男性和女性說話者具有相似的錯誤率。
乍看之下這種方法大有問題,因為此類訓(xùn)練思路似乎嚴(yán)重偏向宗教的世界觀。但 Meta 表示情況并非如此,“雖然錄音內(nèi)容涉及宗教,但我們的分析表明,產(chǎn)出的模型并不會生成更多宗教語言。猜測這是因為我們使用了連接主義時間分類(CTC)方法,與語音識別類大語言模型(LLM)或序列到序列模型相比,前者受到的限制要大得多。”此外,盡管大多數(shù)宗教錄音都是由男性朗讀,但也不會引入男性偏見——模型在女性和男性單色中同樣表現(xiàn)出色。
相比同類模型,MMS 單詞錯誤率更低
在訓(xùn)練出能夠使用這些數(shù)據(jù)的對齊模型之后,Meta 又引入 wav2vec 2.0,可通過未標(biāo)注的數(shù)據(jù)進行訓(xùn)練。非常規(guī)數(shù)據(jù)源和自監(jiān)督語音模型相結(jié)合,最終帶來了令人印象深刻 的結(jié)果。“我們的結(jié)果表明,與現(xiàn)有模型相比,大規(guī)模多語言語音模型表現(xiàn)良好,覆蓋的語言數(shù)量是現(xiàn)有模型的 10 倍。”具體來看,Meta 將 MMS 與 OpenAI 的 Whisper 進行比較,實際結(jié)果超出預(yù)期。“我們發(fā)現(xiàn)在 MMS 數(shù)據(jù)上訓(xùn)練的模型將單詞錯誤降低了一半,而 MMS 涵蓋的語種數(shù)量則增長至 11 倍。”
Meta 公司警告稱,這套新模型并不完美。“例如,語音轉(zhuǎn)文本模型在特定的單詞或短語上可能存在一定的錯誤轉(zhuǎn)錄風(fēng)險。根據(jù)輸出結(jié)果,這可能會導(dǎo)致攻擊性和/或不準(zhǔn)確的表述。我們?nèi)匀幌嘈牛麄€ AI 社區(qū)的協(xié)作對于負責(zé)任開發(fā) AI 技術(shù)至關(guān)重要。”
考慮到 Meta 已經(jīng)發(fā)布了這套開源研究的 MMS 模型,希望它能扭轉(zhuǎn)因科技巨頭的支持習(xí)慣而逐漸將全球使用語言縮減至 100 種以下的趨勢。以此為契機,輔助技術(shù)、文本轉(zhuǎn)語音(TTS)甚至 VR/AR 技術(shù),也許將給每個人都塑造出能用母語表達和學(xué)習(xí)的世界。Meta 表示,“我們設(shè)想一個依靠技術(shù)帶來相反效果的世界,鼓勵人們保持自己母語的活力,通過自己最熟悉的語言獲取信息、使用技術(shù)。”
Meta 的結(jié)果表明,大規(guī)模多語言語音模型優(yōu)于現(xiàn)有模型,覆蓋的語言數(shù)量是現(xiàn)有模型的 10 倍。Meta 通常專注于多語言:對于文本,NLLB 項目將多語言翻譯擴展到 200 種語言,而 Massively Multilingual Speech 項目將語音技術(shù)擴展到更多語言。
Meta 表示該款大模型相比于 OpenAI 的同類產(chǎn)品單詞錯誤率少了一半。
在與 OpenAI 的 Whisper 的同類比較中,我們發(fā)現(xiàn)在 Massively Multilingual Speech 數(shù)據(jù)上訓(xùn)練的模型實現(xiàn)了一半的單詞錯誤率,但 Massively Multilingual Speech 涵蓋的語言是其 11 倍。這表明與當(dāng)前最好的語音模型相比,我們的模型可以表現(xiàn)得非常好。
Meta AI 在大語言模型路上越走越遠
在硅谷這場愈演愈烈的 AI 大戰(zhàn)中,一直 All in 元宇宙的 Meta 正在加速追趕OpenAI、谷歌、微軟等大模型先行者們。
今年 2 月 24 日,在火遍全球的 ChatGPT 發(fā)布 3 個月后,Meta 在官網(wǎng)公布了一款新的人工智能大型語言模型LLaMA,從參數(shù)規(guī)模來看,Meta 提供有 70 億、130 億、330 億和 650 億四種參數(shù)規(guī)模的 LLaMA 模型,并用 20 種語言進行訓(xùn)練。
Meta 首席執(zhí)行官馬克·扎克伯格表示,LLaMA 模型旨在幫助研究人員推進工作,在生成文本、對話、總結(jié)書面材料、證明數(shù)學(xué)定理或預(yù)測蛋白質(zhì)結(jié)構(gòu)等更復(fù)雜的任務(wù)方面有很大的前景。
Meta 首席 AI 科學(xué)家楊立昆(Yann LeCun)表示,在一些基準(zhǔn)測試中,LLaMA 130 億參數(shù)規(guī)模的模型性能優(yōu)于 OpenAI 推出的 GPT3,且能跑在單個 GPU 上;650 億參數(shù)的 LLaMA 模型能夠和 DeepMind 700 億參數(shù)的 Chinchilla 模型、谷歌 5400 億參數(shù)的 PaLM 模型競爭。
4 月 19 日,Meta 宣布開源DINOv2視覺大模型。據(jù)悉,DINOv2 是一最先進的計算機視覺自監(jiān)督模型,可以在深度估計、語義分割和圖像相似性比較等任務(wù)中實現(xiàn) SOTA 級別的性能。該模型可以借助衛(wèi)星圖像生成不同大洲的森林高度,在醫(yī)學(xué)成像和作物產(chǎn)量估算等領(lǐng)域具有潛在應(yīng)用。
5 月 10 日,Meta 宣布開源可跨越六種感官的大模型ImageBind,新的 ImageBind 模型結(jié)合了文本、音頻、視覺、運動、熱和深度數(shù)據(jù)。該模型目前只是一個研究項目,展示了未來的人工智能模型如何能夠生成多感官內(nèi)容。通過利用多種類型的圖像配對數(shù)據(jù)來學(xué)習(xí)單個共享表示空間。該研究不需要所有模態(tài)相互同時出現(xiàn)的數(shù)據(jù)集,相反利用到了圖像的綁定屬性,只要將每個模態(tài)的嵌入與圖像嵌入對齊,就會實現(xiàn)所有模態(tài)的迅速對齊。
Meta 力求通過這樣密集的發(fā)布向外界證明自己還一直跑在 AI 賽道中。
然而,在燒光了幾十億美元義無反顧押注元宇宙后,Meta 在 AI 方面的能力還是受到了外界的質(zhì)疑。
在 Meta 公司今年 4 月的季度財報電話會議上,公司 CEO 扎克伯格明顯相當(dāng)被動。砸下數(shù)十億美元、被寄予延續(xù)帝國輝煌厚望的元宇宙愿景還沒來得及初試啼聲,就被圍繞人工智能(AI)掀起的洶涌狂潮搶了風(fēng)頭,剎那淪為明日黃花。
批評者們注意到就連 Meta 自己的底氣也有所減弱,扎克伯格去年 11 月和今年 3 月兩份聲明間的口吻大為改變。之前扎克伯格強調(diào)這個項目屬于“高優(yōu)先級的增長領(lǐng)域”,而今年 3 月則轉(zhuǎn)而表示“推進 AI”才是公司的“最大單一投資方向”。
但扎克伯格本人還是做出了澄清,表示“有人認為我們正以某種方式放棄對元宇宙愿景的關(guān)注,我想提前強調(diào),這樣的判斷并不準(zhǔn)確。”
“多年以來,我們一直專注于 AI 和元宇宙技術(shù),未來也將繼續(xù)雙管齊下……構(gòu)建元宇宙是個長期項目,但我們的基本思路將保持不變、努力方向也不會動搖。”
參考鏈接:
https://www.engadget.com/metas-open-source-speech-ai-recognizes-over-4000-spoken-languages-161508200.html
https://ai.facebook.com/blog/multilingual-model-speech-recognition/
本文轉(zhuǎn)載來源:
https://www.infoq.cn/article/hKdP04SgxzysSXSzwYVw
