
中國團隊推出腦電圖圖像生成模型 DreamDiffusion,清華、騰訊參與研究
作者 | IT之家2023-07-05
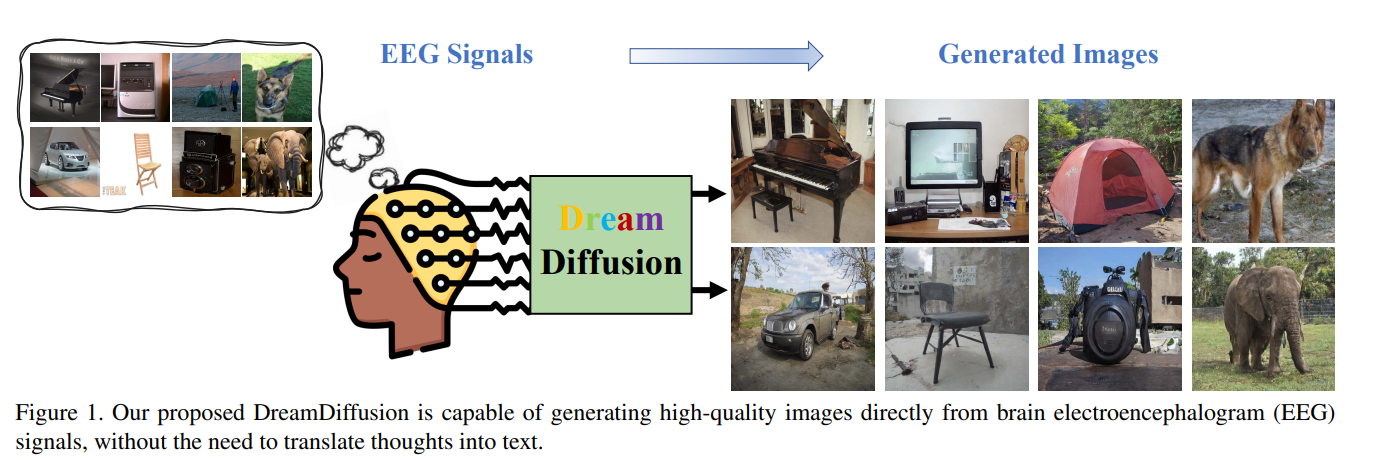
清華大學深圳國際研究生院、騰訊人工智能實驗室(AI Lab)和鵬城實驗室的研究人員近日發表論文稱,研究團隊開發了一個名為 DreamDiffusion 的圖像生成模型,該模型可以直接通過腦電圖(EEG)信號生成高質量圖像。相關論文發表于美國康奈爾大學旗下在線學術論文平臺 arXiv 上。
▲ 圖源 研究團隊論文(下同)
目前已有不少團隊研究了使用文本到圖像的擴散模型從人腦生成圖像的方法,但大多數采用的都是功能性磁共振成像(fMRI)技術捕捉大腦活動從而生成圖像。這種技術缺乏實用性,因為它需要專家操作并且需要昂貴且難以攜帶的 fMRI 設備。
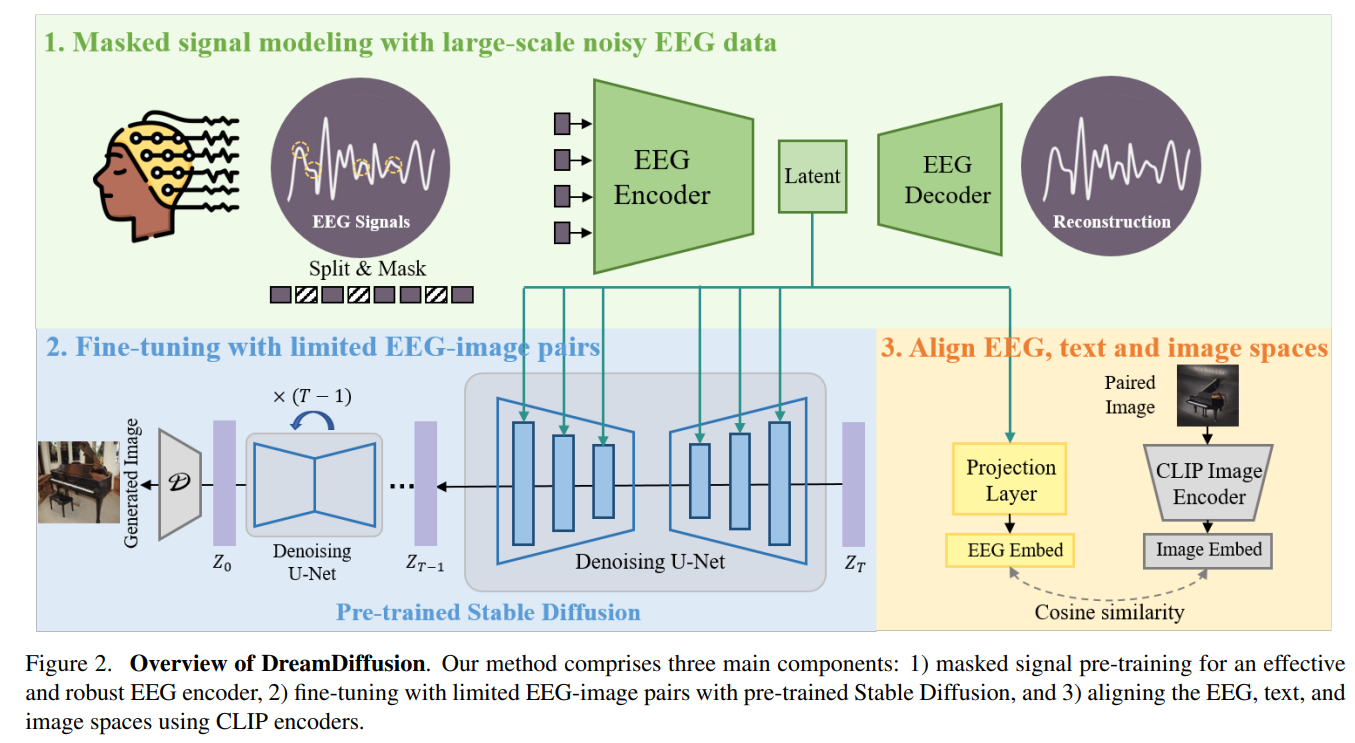
相比之下,腦電圖是一種記錄大腦電波活動的非侵入性、低成本方法,且已有一些便攜式商業產品可以輕松采集腦電圖信號。于是,研究團隊提出了一種“穩定擴散”的圖像生成方法,能夠減少腦電圖信號的噪聲干預,使擴散模型的預訓練更穩定有效。
研究團隊向 6 位受試者展示了屬于 40 個不同對象類別的 2000 張圖像,進而通過采集受試者的腦電圖信號來生成高質量圖像。下圖中每組左邊標有 GT 的是原始圖像,右邊的 Sample 圖像為腦電圖生成圖像。

為了評估該方法的準確性,研究團隊將其與最近的另一項類似研究 Brain2Image 進行了定性比較,結果證實,其準確率明顯高于 Brain2Image 生成的圖像,從而證明了該方法的有效性。
熱門文章
3
10
11
12
14
15
16
2周前
20
