此前市場有消息稱華為大模型“盤古 Chat”已申請相關商標,將于 7 月 7 日發布,而華為官方表示不會有“盤古 Chat”此類命名。
華為輪值董事長胡厚崑出席參加了今日 2023 世界人工智能大會開幕式并發了表演講。他 表示:華為將在 7 月 7 日的華為云開發者大會上推出盤古大模型 3.0。
據介紹,從通用大模型走向行業大模型。基礎大模型,行業大模型,場景模型。盤古大模型已經深耕行業 10+,業務場景 400+。
他表示,去年年底 ChatGPT 的出現,把人工智能推向了新的風口。人工智能將幫助我們改寫身邊的一切。
他介紹了華為在人工智能方面的布局,在深耕算力方面實現了架構創新、發展生態、共建算力;在架構創新上重新定義計算架構,對等平構架構節點性能提升 30%,昇騰 AI 集群效率提升 10%。
此外,華為在發展生態上還聯合 5700 + 鯤鵬 / 昇騰合作伙伴,以及硬件合作伙伴 30+,實現了國內大模型近一半創新使能,包括場景化系列 AI 硬件 100+,孵化 / 適配大模型 30+,鯤鵬 / 昇騰開發者 380 萬 +。
在共建算力方面,他表示華為已經在構建城市算力基礎設施,幫助各地政府打造了 25 個昇騰人工智能計算中心。
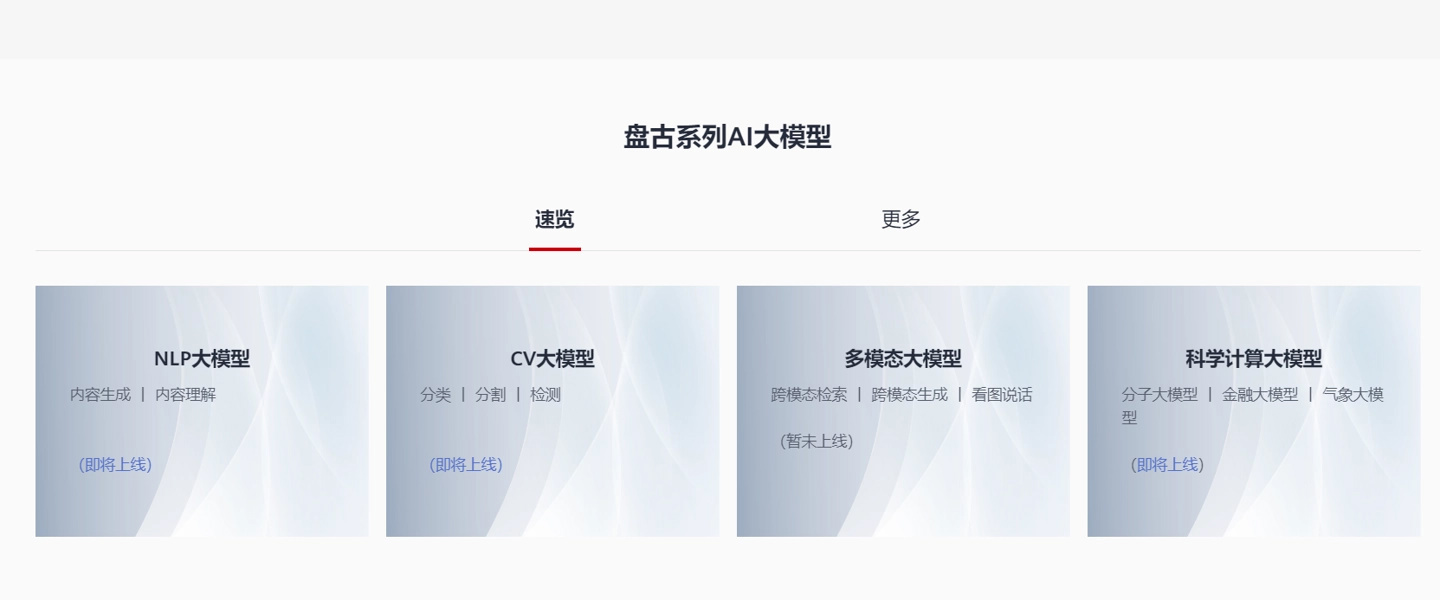
公開資料獲悉,華為盤古系列基礎大模型于 2021 年正式對外發布,包括 NLP(自然語言處理)、CV(機器視覺)和科學計算大模型;后續又發布了礦山、藥物分子、氣象、海浪等行業大模型。
據介紹,NLP 是首個千億參數中文預訓練大模型,CV 大模型則首次達到 30 億參數。盤古 CV 大模型業界最大 CV 大模型、首次實現兼顧判別與生成能力、在 ImageNet 上小樣本學習能力上的業界第一;盤古氣象大模型提供秒級天氣預報;紫東.太初是全球首個圖、文、音三模態大模型。

對于盤古大模型定位,華為內部團隊確立了三項最關鍵的核心設計原則:一是模型要大,可以吸收海量數據;二是網絡結構要強,能夠真正發揮出模型的性能;三是要具有優秀的泛化能力,可以真正落地到各行各業的工作場景。
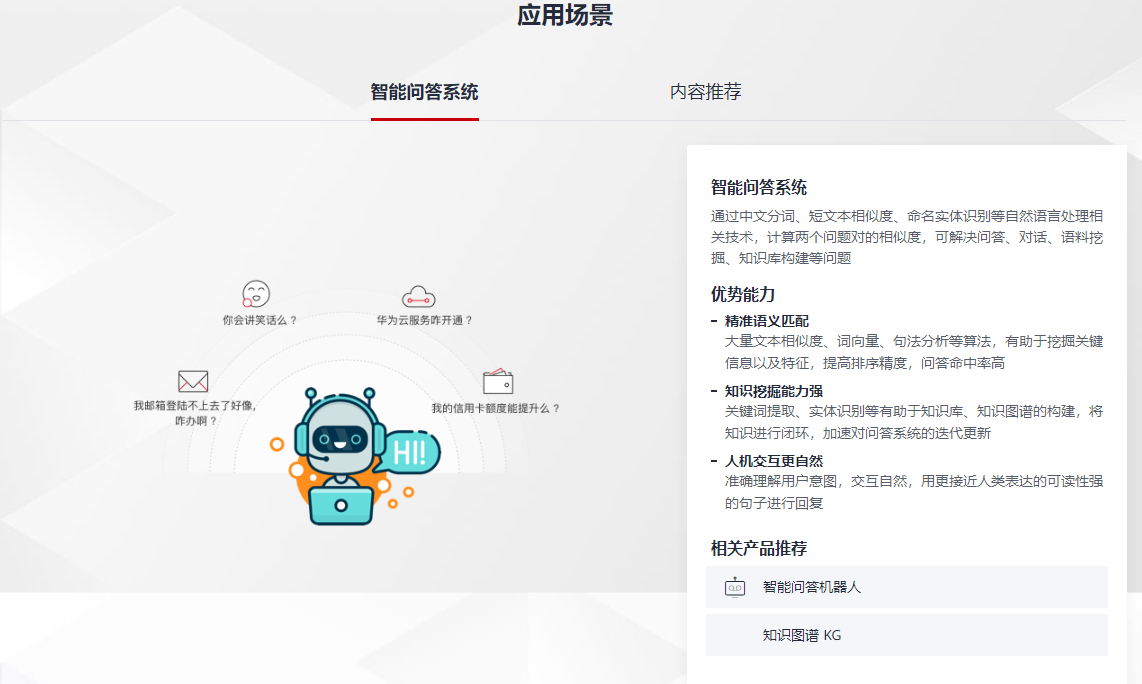
華為云官網顯示,盤古大模型由 NLP 大模型、CV 大模型、多模態大模型、科學計算大模型等多個大模型構成,通過模型泛化,解決傳統 AI 作坊式開發模式下不能解決的 AI 規模化、產業化難題,可以支持多種自然語言處理任務,包括文本生成、文本分類、問答系統等等。

華為表示,盤古 NLP 大模型由華為云、循環智能和鵬城實驗室聯合開發,具備領先的語言理解和模型生成能力:在權威的中文語言理解評測基準 CLUE 榜單中,盤古 NLP 大模型在總排行榜及分類、閱讀理解單項均排名第一,刷新三項榜單世界歷史紀錄;總排行榜得分 83.046,多項子任務得分業界領先,向人類水平(85.61)邁進了一大步。
具體來看,盤古 NLP 大模型首次使用 Encoder-Decoder 架構,兼顧 NLP 大模型的理解能力和生成能力,保證了模型在不同系統中的嵌入靈活性。下游應用中,僅需少量樣本和可學習參數即可完成千億規模大模型的快速微調和下游適配,這一模型在智能輿論以及智能營銷方面都有不錯的表現。