企業(yè)在開發(fā)及實施大模型應用過程中,面臨四大挑戰(zhàn):
● 首先,數據準備時間長,數據來源分散,歸集慢,預處理百TB數據需10天左右;
● 其次,多模態(tài)大模型以海量文本、圖片為訓練集,當前海量小文件的加載速度不足100MB/s,訓練集加載效率低;
● 第三,大模型參數頻繁調優(yōu),訓練平臺不穩(wěn)定,平均約2天出現(xiàn)一次訓練中斷,需要Checkpoint機制恢復訓練,故障恢復耗時超過一天;
● 最后,大模型實施門檻高,系統(tǒng)搭建繁雜,資源調度難,GPU資源利用率通常不到40%。
華為順應大模型時代AI發(fā)展趨勢,針對不同行業(yè)、不同場景大模型應用,推出OceanStor A310深度學習數據湖存儲與FusionCube A3000訓/推超融合一體機。

華為數據存儲產品線總裁 周躍峰
OceanStor A310深度學習數據湖存儲,面向基礎/行業(yè)大模型數據湖場景,實現(xiàn)從數據歸集、預處理到模型訓練、推理應用的AI全流程海量數據管理。
OceanStor A310單框5U支持業(yè)界最高的400GB/s帶寬以及1200萬IOPS的最高性能,可線性擴展至4096節(jié)點,實現(xiàn)多協(xié)議無損互通。全局文件系統(tǒng)GFS實現(xiàn)跨地域智能數據編織,簡化數據歸集流程;通過近存計算實現(xiàn)近數據預處理,減少數據搬移,預處理效率提升30%。
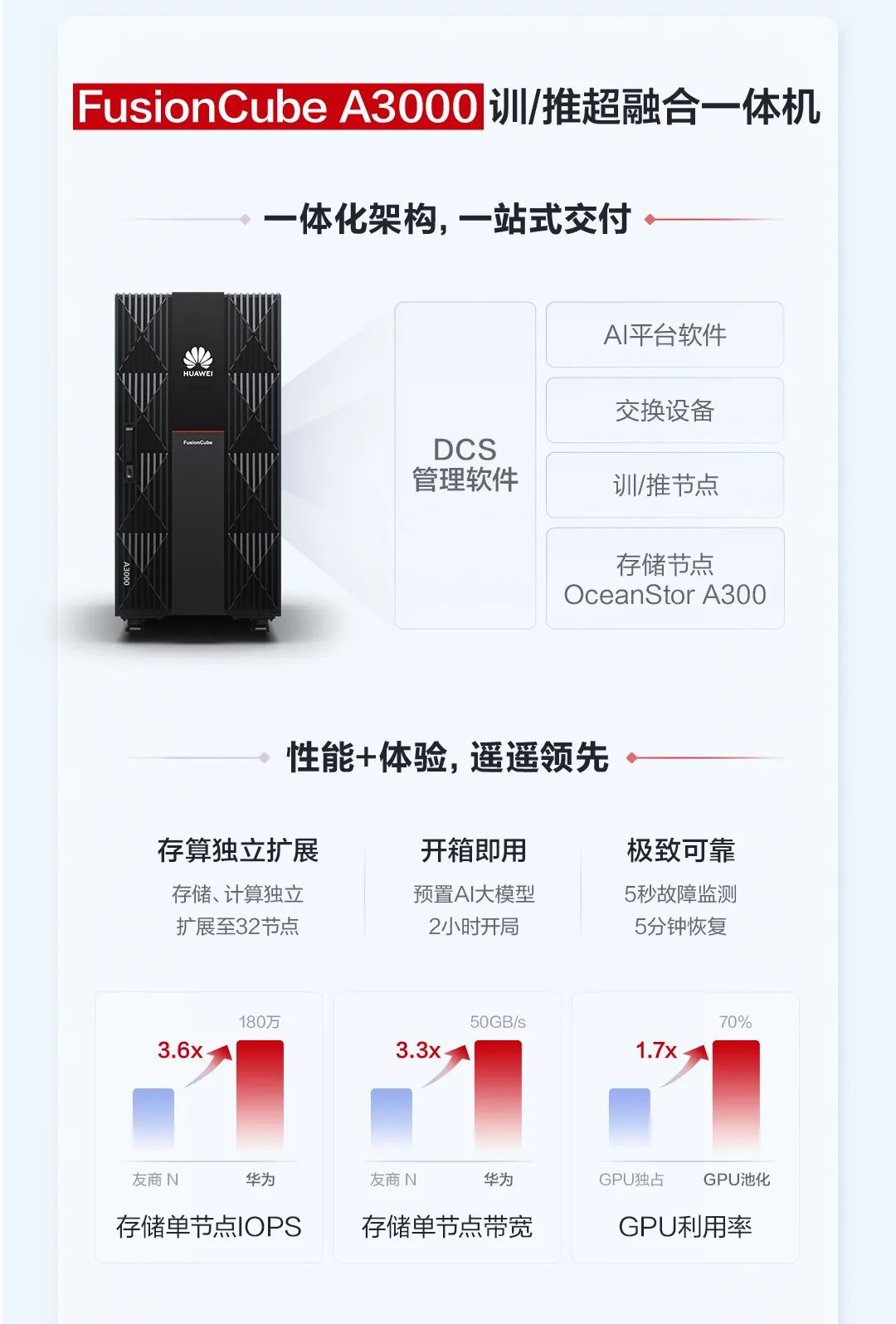
FusionCube A3000訓/推超融合一體機,面向行業(yè)大模型訓練/推理場景,針對百億級模型應用,集成OceanStor A300高性能存儲節(jié)點、訓/推節(jié)點、交換設備、AI平臺軟件與管理運維軟件,為大模型伙伴提供拎包入住式的部署體驗,實現(xiàn)一站式交付。
FusionCube A3000開箱即用,2小時內即可完成部署。訓/推節(jié)點與存儲節(jié)點均可獨立水平擴展,以匹配不同規(guī)模的模型需求。同時FusionCube A3000通過高性能容器實現(xiàn)多個模型訓練推理任務共享GPU,將資源利用率從40%提升到70%以上。FusionCube A3000支持兩種靈活的商業(yè)模式,包括華為昇騰一站式方案,以及開放計算、網絡、AI平臺軟件的第三方伙伴一站式方案。
在本次活動中,中科院自動化所紫東太初大模型中心常務副主任、武漢人工智能研究院院長王金橋;科大訊飛副總裁、AI工程院院長潘青華;智譜AI算法工程師陶治華分別就AI大模型的應用實踐以及基于華為AI存儲的聯(lián)合創(chuàng)新發(fā)表主題演講。

中科院自動化所紫東太初大模型中心常務副主任
武漢人工智能研究院院長 王金橋

科大訊飛副總裁、AI工程院院長 潘青華

智譜AI算法工程師 陶治華
華為數據存儲產品線總裁周躍峰表示:大模型時代,數據決定AI智能的高度。作為數據的載體,數據存儲成為AI大模型的關鍵基礎設施。華為數據存儲未來將持續(xù)創(chuàng)新,面向AI大模型時代提供多樣化的方案與產品,攜手伙伴共同推進AI賦能千行百業(yè)。
下滑了解更多發(fā)布會精彩內容