
金秋9月,智次方與智用人工智能應用研究院攜手推出AI大模型系列公開課,從認知、應用、商業、安全等不同方向,帶您領略AI大模型的魅力與應用前景。
9月6日晚,智用研究院首席數字規劃師 趙銘老師以“AI新視界:揭開AI大模型的黑魔法面紗”為主題進行了一次深度內容分享。
以下根據直播內容整理:
01
“大模型”的進化歷程
人工智能的領域非常廣泛,基本上在計算機科學領域中,能夠模仿人類思維和決策的都被稱為人工智能。這個領域非常龐大,其中有許多不同的方法,但最終都可以實現類似的功能。
在上世紀90年代左右,出現了一種叫做機器學習的流派。其思想是如果我們把好多歷史數據輸入到模型中,它就可以幫我們生成一條趨勢線,類似于股票的K線圖,我們可以用它來預測未來可能發生的事情。
到了大約2010年前后,在機器學習領域中出現了一個小流派——深度學習。人們開始使用一種新的架構來實現趨勢的發現,這個架構叫做深層神經網絡。這個架構是從模擬人類思維方式、模擬人類大腦中得來的。隨著大家對大腦的了解越來越多,發現大腦皮層中有很多神經元,雖然不知道這些神經元如何工作,但是我們可以模仿神經元來構建多層神經網絡,一層一層地將一個大任務分解成許多小任務,讓許多神經元一起工作。基于這個理念,人們開始研究生成神經網絡算法和框架,這就是深度學習的起源。
深度學習強調“遷移學習”的概念。不要被這些聽起來很高大上的名詞迷惑,遷移學習的原理也很簡單。以前的機器學習想法是,如果我研究了過去的股票價格,我就能預測未來的股市會漲還是跌。遷移學習的思想類似于如果我研究了股票市場的漲跌,我是否也可以用這個模型去預測期貨市場,或者用這個模型去預測貨幣市場。目的是用一個任務學習知識,然后將這個知識應用到另一個任務中,就像學習可以遷移一樣。
隨著深度學習的繼續發展,大家慢慢發現無論如何研究下去,最基礎的模型的共性是一樣的。我們稱這一類非常基礎的、有共性的模型為“基礎模型”。實際上,基礎模型并不新穎,已經出現很多年了。其實大家每天都在接觸基礎模型,比如,有人在開新款的新能源的車型,它有L2級別的自動駕駛,這一功能是靠車里面的攝像頭或傳感器,來探測前方是否有障礙物,探測車道的位置,然后使得車輛行駛在道路中間。這是視覺探測。視覺探測就是生成神經網絡里面的基礎模型在運作,也是Resnet做的事情,或者說基于Resnet衍生出來的大量圖像識別技術、視頻識別技術,都是在基礎模型之上做出來的。
在基礎模型的發展中,就開始出現了大模型。實際上大模型就是基礎模型里面的一個分類。那么為什么叫它“大”呢?是因為以前的基礎模型沒有用到那么多的數據和參數。而大模型里面用到的模型非常特別,它用到了大量的數據、大量的計算,而且具有大范圍的通用性。
為了讓大家對“數據到底有多大”有一個感性的認識,我來舉個例子。支撐你每天完成L2級別自動駕駛的Resnet這種圖像識別技術一般用到多少參數?它的參數級別大概是個位數的億,比如說2億到5億這樣一個級別。當然,現在的視覺引擎,比如說有一些攝像頭可以識別到人有沒有在笑,這個人的年齡到底是50歲還是30歲,這都是基于Resnet類似的技術發展出來的。它的參數也會越來越多,但再怎么多其實也就是在幾億到幾十億這樣一個參數。到達十幾二十億參數的,說明這個圖像模型已經非常強大了。
但是我們今天講的大模型,是一個叫Transformer的模型。這個模型非常強大,它的參數可以達到多少呢?它是以幾十億為起步的。我們經常聽到的是65億個參數。但這只是它的起步值,而我們現在主流使用的大模型,能夠完成一些繪畫任務的,基本上都在百億甚至千億級別。當然,今天很多人使用的ChatGPT模型,一般達到什么參數級別呢?至少是百億起步,而百億只是起步點。作為一個玩家,如果你想要做得更好,你需要有大幾百億的參數量,甚至到千億級、萬億級。
實際上,業界已經開始探討萬億級參數的某些大模型要大到什么程度,既然參數量如此之大,計算量也非常驚人,以前我們的那些視覺訓練,可能只需要一臺電腦和一張好一點的顯卡就可以運行。但如今我們發現英偉達公司非常厲害,只有他們的機器才能運行Transformer模型,而且不是一臺機器,是一個由多臺機器組成的集群來運行。這是因為它的數據量和參數量太大了,只有這樣龐大的機器才能承受。但一旦運行起來,你會發現它非常強大,可以支持很多東西,這也完美的詮釋了我們剛才提到的遷移學習的任務。你讓它訓練中文,然后你會發現它也能用英文完成任務。你讓它訓練古詩詞,然后你會發現它也可以用于寫其他古代文學。你讓它來訓練醫學,你會發現它也能稍微懂一點法律。只要給它足夠的語料來訓練,它的遷移學習就能做得非常好。
這就是從機器學習發展到現在大模型的發展歷程。
02
人工智能發展的3要素
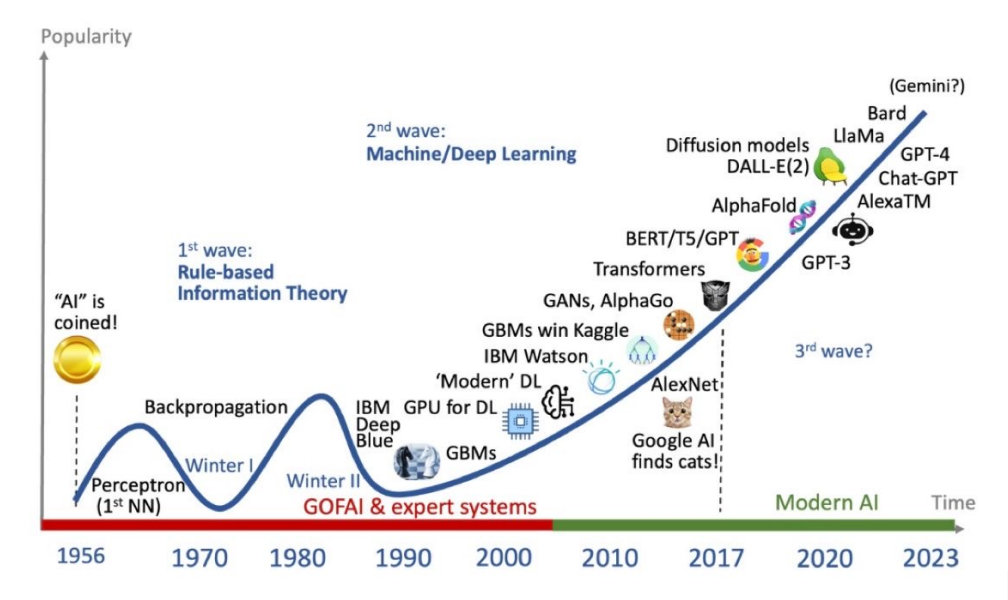
接下來,我們將時間軸拉開,可以在這張圖中看到人工智能發展過程中每一個技術出現的時間點。我剛才有講到一些,大家有沒有注意到2017年就開始出現了Transformer,所以并不是今天有了ChatGPT才有了Transformer。也就是說,它已經發展了五六年,才最終從理論變成了我們今天可以使用的應用。
而剛才講到的大模型,或者說基于大模型基于的基礎模型最厲害的地方在于它的遷移學習能力,但是遷移學習能力最關鍵的來自于人工智能發展的三個要素:數據、算法和算力。這三個要素就像一個三角形,它們互相制約、互相支持,共同發展。
以數據為例,很多年前,當我們談到數據時,大家通常想到的是數據庫,里面存放個表。即使你不從事IT行業,每天使用 Excel 表格也是在使用數據。后來,我們發現除了數據庫或者 Excel 表格之外的其他東西也可以被視為數據。比如說,你提供給我一個文件,員工手冊或產品說明書,這些PDF文件也可以被視為數據。我現在說話的語音也是數據,大家拍照的面部特征也是數據。我們將這些數據匯總到一起,就可以形成一個數據湖。從數據庫到數據倉庫再到數據湖,業界的發展趨勢是慢慢的海納百川,逐漸涵蓋一切類型的數據。
那這些數據一定有方法去處理它,這就是我們要講到的算法。算法的發展也十分有趣。早期,我們使用數學的方式來教計算機如何處理數據。例如,我們用數學告訴計算機什么是加法,一加一等于二就是加法。我們以前使用的所有算法,無論是最簡單的歸納總結還是最復雜的預測,其實都是有數學理論作為基礎支撐的。一定是數學家先提出數學公式,然后我們計算機工程師才能寫出算法。因此,實際上整個行業在過去30年是數學引領了計算機的發展。
大約從2010年開始,情況已經不同了,因為計算機中出現了一些新的算法,這些算法是數學解釋不了或無法解釋的。由于深層神經網絡的出現,就像我們人類一樣,盡管我們的神經學或生物學再怎么發達,我們仍然無法解釋它們是如何運作的。現在的生成神經網絡到底是如何運作的?一旦規模擴大,以我們人類目前的理解能力和數學建模能力,就很難提供一個清晰的解釋。這也是為什么當2017年Transformer模型出現時,業界一開始并不了解它的潛力。
但大約在2019年和2020年,當Transformer模型的規模達到一定程度時,以GPT 3為代表,達到了千億級別的參數量,GPT 3的參數級別大約在1700多億。人們發現,你以為你知道這個Transformer模型的工作原理,但實際上你不知道,你發現它好像可以推理,好像能做許多你沒有教過它的事情。從這個時候開始,人們慢慢發現數學不再那么容易解釋了。如果再過十年、二十年,我不知道未來的世界會是什么樣子,但當我們回顧2020年到2023年時,人們會發現這是一個分水嶺,人工智能、科學、數學這樣一個分水嶺。
但是有了這么奇妙的算法,你需要有地方能夠計算它,對不對?《三體》里面講過,我們最早的可以用人來代替計算機里面的計算單元,用人來代替晶體管好像也能干完一些事情,但是對于像神經網絡算法,就不能再用簡單的晶體管來計算了。
在這種情況下,提高算力必須通過提高三角形中的“數據”和”算法”。GPU以前我們主要用來做游戲,對不對?后來發現算法特別是神經網絡算法,它不像CPU那樣依賴于執行,我們可以把一張圖切成幾千個、幾萬個,然后讓每個處理器獨立處理,這樣會更快。當GPU有幾十個核時,CPU可能只有兩個或四個核。這就是為什么在20世紀90年代和本世紀初,越來越多的人開始使用GPU。除了GPU之外,現在還有一些專用芯片,專門用于人工智能,它不需要干其他事情,只需要處理人工智能。這是特殊芯片的算力的發展。
隨著云計算、邊緣計算等技術的發展,有時候是數據跑得多快一點,有時候是算法跑得快一點,但這個三角形中的三個要素永遠都在相互發展。
今天我主要分享的是中間的一環算法,特別是其中的Transformer。
03
OpenAI的脫穎而出
GPT中的T其實就是Transformer,是ChatGPT把它帶火的。ChatGPT可以在兩個月把用戶量突破到1億,基本上已經沒有其他的應用能夠跟它比肩的了。
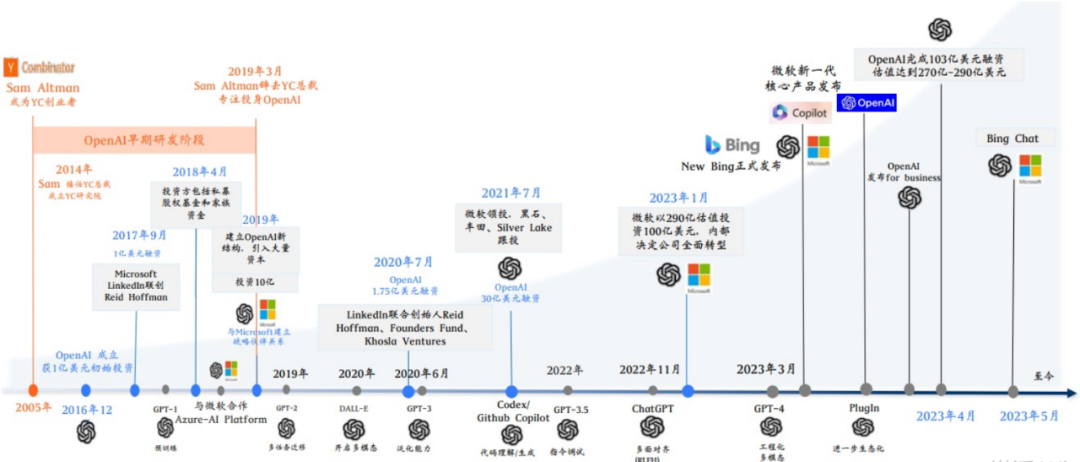
讓我們來看看開發ChatGPT背后的公司OpenAI,其中比較重要的時間點是它的成立,包括被微軟投資。實際上它并不是唯一一家,也不是第一家做大模型的公司。同時,還有其他幾家公司在這個領域有影響力的包括谷歌、Facebook(現在叫Meta)等公司都在做大模型。
你們可能會好奇為什么OpenAI會脫穎而出。我個人的看法是,首先,他們的工程化讓大模型往前邁進了很大很大的一步。什么是工程化模型?你可以把這個模型看成是一個天賦異稟的小孩子,他可能一出生就有180的智商,你讓他學什么,他就學什么。這個過程就像是在公開教育這個小孩子,但是如果你教得慢,他在9歲時可能就被其他人甩在了后面。雖然他天賦異稟,但如果教得不好,他的思維年齡可能現在還停留在6歲或7歲,這樣一來就會落后了。也許大家最初的思路都是基于同一份論文,就是誰家教的好的問題,也是工程化做得好的問題。
04
傳統機器學習的套路
在講Transformer之前,我想先介紹一下機器學習是如何完成這些工作的,以及如何將一個算法轉化為可用的。大家千萬不要認為機器學習聽起來很高端,實際上它很簡單。
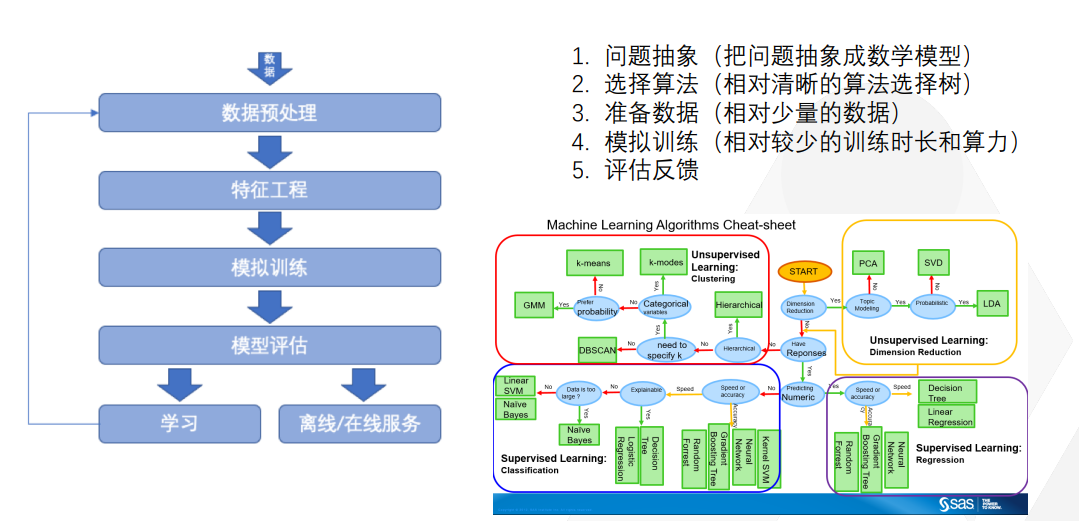
首先,你需要提出你的問題,比如說我要預測股票的價格從哪個期貨市場賺錢,這就是我的問題。將其抽象成一個數學模型,比如說我使用數學中的歸納算法模型,如果我能夠歸納得足夠豐富、足夠準確,我就能夠猜出明天的股票價格。
第一步是問題抽象,第二步是選擇算法。算法有很多種,選出來之后,你需要準備數據。爬下來所有交易所的數據,甚至是一級、二級市場的數據。傳統機器學習用相對于較少的數據,來推斷未來的規律。使用相對較少的訓練時長和算力來對模型進行訓練。模型訓練完成后需要進行評估和反饋。慢慢地讓模型越來越趨向真實,就像你畫一幅畫一樣。這是傳統機器學習的套路,但Transformer模型并不是這樣的,大家會發現中間有很多可以學習的新名詞和方法。
05
理解Transformer算法相關的概念
GPT的“G” 指的是生成式,“P”指的是預訓練。因此,它被稱為生成式預訓練transformer。首先需要預訓練這個transformer模型,這個訓練需要專門的語料庫,需要人工進行標記的語料庫。此外,還需要人工反饋。例如,您向 GPT 提出一個問題,它給出兩個答案,然后需要人工去告訴它哪個答案更好,這樣它就會在下一次回答時會表現得更好。這是一個正向反饋循環。
預訓練是通過大規模、海量的通用文本,來讓模型學到廣泛的通用知識和上下文的理解。具體是什么意思?如果我現在讓 ChatGPT 寫一篇文章,它可以寫,我讓它寫古詩,它也可以寫。但它真的能讀懂古詩嗎?或者,如果我讓它寫文案,它真的懂法律條文嗎?實際上,它不理解這些,它只知道每個字出現的概率。
我們經常聽到在大模型里面,某某公司很厲害,基于一個模型做了微調。
微調是什么意思呢?原本這個模型是個通用模型,可以做任何事情。然而,當你問它一些特定的問題時,它可能不懂。例如,如果我問它中國的古詩詞,它可能不懂。但是,如果我提供大量的中國古詩詞進行微調,它就能更好地理解中國古詩詞,知道當你要寫七言古詩時,需要規律是什么,押韻是什么樣子的。這就是微調。
因此,微調實際上是遷移學習的理念,將通用學習微調到能夠遷移支持另一個領域,讓其理解,包括語言的微調,例如理解中文之后,它幾乎也可以理解日語,理解英語,也可以理解法語。如果加入中英文對照的語料進行微調后,它也可以理解中文。
但是放心,我們今天的大模型,至少到目前為止,這個Transformer模型并沒有真正的理解能力,沒有科幻小說中的自主決策能力。我今天揭開AI大模型的面紗,讓大家知道這一點:大模型沒有真正的理解能力,它只判斷出現的概率。
最后一個概念是參數。我們之前提到了千億參數,幾十億參數。我今天所說的每句話、每個字后面都是在一個龐大的向量網絡來支撐。比如“我是誰”,這個“我”字后面有一個龐大的向量宇宙來支撐它。向量怎么理解呢?可以想象一下多維宇宙。我們所處的宇宙是三維的,加上時間維度可能是四維的,還可以有其他維度。在數學中,我們可能會有一個多維的數學網宇宙,不用管它是什么,只需要知道可能有很多維度。
所以,如果我把一篇金庸小說輸入到模型中,它會經常發現中間有些字詞是相關聯的,比如說,“九”字后面經常會跟著“陽”或者“陰”,“九陽正經”、“九陰真經”,那么“九”字的向量數據庫里面,向量網絡里面就一定有“陽”或者“陰”出現。這兩個字老是出現在一起,對不對?這是金庸小說中的常見模式。所以當我詢問金庸小說里面哪個武功最強時,如果我給出“九”這個提示,模型就會立刻判斷。從概率角度來看,你肯定想我回答“九陽”或“九陰”,這個概率最大,不會回答其他的東西,比如“九九艷陽天”之類的,對吧?這就是一個概率問題。所以,向量代表的就是這個字與其他字發生關系的概率有多大。
因此,你可以設想,如果我的向量網絡的維度越多,那么我的向量就越復雜。這是否意味著,我能夠用這個向量網絡來記錄一個龐大的語料庫,這個語料庫可能比中國國家圖書館和大英國家圖書館的所有書加起來還要大,其中每個字與其他字發生關系的概率都能被記錄下來。這樣,當我需要回答“莎士比亞文體中哈姆雷特到底得罪了多少人”這類問題時,我就能從哈姆雷特的向量網絡中輕松找到答案,這只是一個概率問題。通過這種方式,大家應該能夠輕松理解參數所代表的是每個字與其他字發生關系的概率。有了這樣的基礎理解之后,我們就能輕松理解Transformer算法了。
06
Transformer算法架構的工作原理
這是一個最基本的 Transformer 結構圖。不要以為它很復雜,用我剛才講給大家的知識,一講解大家就理解了。
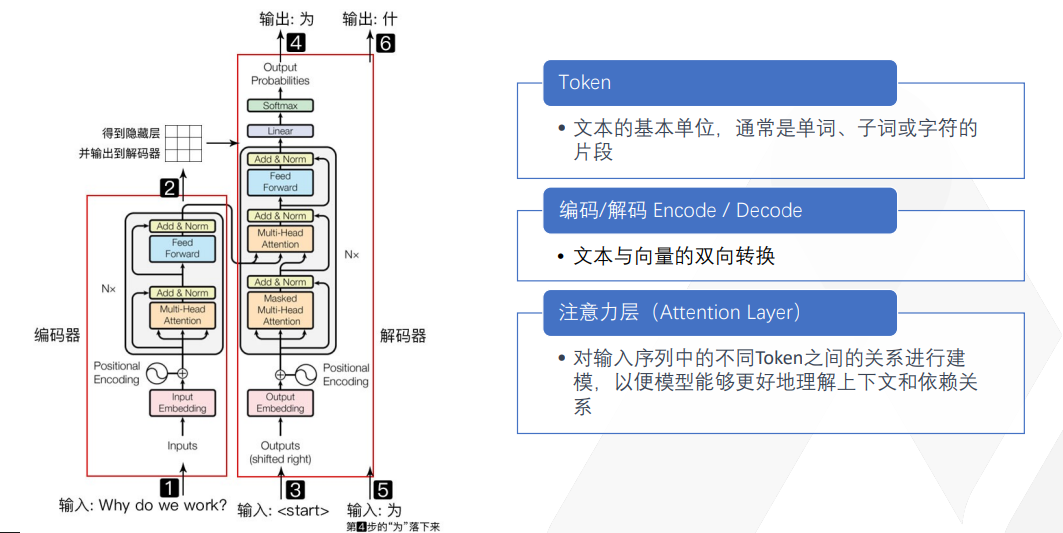
這里舉的一個例子是讓 GPT 幫我翻譯英語到中文,將“why do we walk”翻譯為“為什么我們要工作?”這是我們打工人的永恒問題。我的輸入是一句英文輸出,它得輸出成中文。那我們來看看這個Transformer 算法怎么做?
首先,它把你的輸入先拆成token。token在中文里好像不太好直接翻譯,我就直接叫它 token。
在英語里,token 通常就是一個單詞,其實在中文里面就是一個字。比如“我來自于哪里?”就可以拆成“我”一個 token,“來”一個 token,“自”一個 token,“于”一個 token,“哪”一個 token,“里”一個 token。英語有時候一個字還不止一個 token,因為英國人為了表達一個沒見過的概念,有時候就把好多個英語單詞組成一塊。如果你們考過美國的托福、GRE 考試,就會見到那種特別長二三十個字母的英文單詞。這種單詞通常會進入到Transformer算法,然后把它切成好多個塊,每個塊代表了一個意思,每個塊就是一個 token。所以英語經常會一個字是幾個 token,而中文基本上一個字就是一個 token。
拆完之后,每一個 token 對應了一個向量的多維空間。就像我剛才舉的例子,一個“我”字后面帶一個向量空間,“九陽真經”這個“九”字后面又有一個向量空間,每個字都有一個向量空間。這個時候我告訴它說,你要幫我翻譯,那它就會先來判斷,說好,這里面出現了“為什么”?“why”是“為什么”?第一個字是“why”,它先輸出個“why”,輸出完“why”之后,它就在“why”的向量空間里去找。
我要表達這個 why 這個意思的話,最大概率的會是什么呢?是為什么?還是為何?還是為了?還是為什么?AI找到了“為什么”這個詞出現的概率最大,因此毫不猶豫地輸出了這個詞。同樣的道理,AI發現概率最大的第三個詞肯定是“么”,于是也將其輸出。
在與ChatGPT聊天時,它不會給你一個完整的句子,而是一個一個字地輸出。它靠每個字去猜下一個字出現的最大幾率,這是一個基于多維向量空間的算法,不是很復雜。
有時候,我們中國人很好奇,AI算法能否區分“南京市長江大橋nán jīng shì cháng jiāng dà qiáo”和“南京市長,江大橋nán jīng shì zhǎng jiāng dà qiáo”的區別。你認為Transformer算法能否區分呢?這是一個非常有趣的問題。
在使用傳統的生成神經網絡時,微軟的一個研究院專門研究如何斷句,因為中文斷句是一個很大的問題。我們需要編寫算法來判斷是將斷點放在“長江大橋”前面還是藏在“zhǎng”的后面。
然而自從出現了Transformer算法,我們發現對于Transformer算法來說,斷句并不重要,它只關注每個字的向量空間。因此,在南京市這個例子中,后面出現的大概率是“長江大橋”,而不是“市長江大橋”。由于“江大橋”出現在“市長”的字后面的概率微乎其微,因此它不太可能被選中。因此,Transformer算法絕對不會將“南京市長江大橋”斷成“南京市長”。
在過去,我們擔心如何斷句,如何理解中文的語義和語法,以及如何理解日語和韓語中的語法等問題。這些問題都是以前使用神經網絡時需要解決的問題。但現在,這些問題都不再是問題,許多從事神經網絡工作的人可能需要轉換方向,轉向Transformer算法方向,因為在這個領域,這些都不是問題。
接下來是Attention Layer注意力層,用于操作處理每個字背后的多維向量空間。這一層被稱為自注意力層,指的是它只關注這個字本身的向量,而無需關注其他內容,如語法、語言和斷句等。因此,我們可以讓算法自行發揮向量空間算法的優勢。
好,現在你們應該理解為什么它可以寫詩,為什么它可以回答問題了。
07
Transformer的獨特之處
傳統的深度學習方法不能做的事情,為什么只有Transformer 才能做到?
為了解答這個問題,我們先思考一下傳統的神經網絡是用來干什么的。我們通常用它來進行自動駕駛視頻識別和圖片識別,為什么呢?因為我們可以將一張圖片輕松地拆成小塊,每個小塊都可以單獨處理,不需要依賴其他的塊,也不需要識別這個小塊和其他小塊之間有多少關聯。如果說沒有關聯也不完全正確,是有關聯的,比如你將前面一輛車的車牌號碼切成許多小塊,必須將它們連起來才能讀出完整的車牌號碼,因此它們之間是有關聯性的。
但是相比于文字,這種關聯性并不那么復雜,因此傳統的深度學習模型只需要挖幾層就挖到底了,不需要挖很多層,也不需要進行復雜的并行處理,只需要將圖片分割成小塊,進行簡單的單線條處理即可。但是對于文本來說,傳統的深度學習模型就不行了。
在處理文本時,我們發現在一句話中,每個單詞放在前面或后面都有完全不同的意思,這在中文中尤其明顯。中文中有各種各樣的梗,比如諧音梗、詞語順序梗等,因此傳統的深度學習模型就蒙了,無法斷句,無法處理順序。它需要將整句話的上下文連起來才能理解意思,因此它無法處理。
而 Transformer 的獨特之處在于其attention 機制(注意力機制),它只關注概率,不關注斷句或順序,只關注下一個字與當前字之間的關系。因此 Transformer 實際上是一種歸納總結的算法,它是一種預測算法,用于預測下一個詞或下一個字出現的概率。而且在處理完后,它解決了并發性問題,因為每個字只關注自己的向量空間和下一個字的向量空間。因此即使你給我一篇文章,我也可以將其拆分成多個小塊進行并行計算,只要我的計算機足夠強大,我就能夠在一秒鐘內理解整篇文章并回答任何問題。Transformer解決了分布式語言處理的問題,真正可以并行處理整篇文章。無論是整本小說還是整個圖書館,只要你的計算能力足夠強,Transformer就能處理。
08
GPT的局限性
GPT 的演進歷程經歷了很長時間,從最初的 1.0 版本發展到現在的 3.5版本、4.0 版本,參數量越來越多。
在這么多年的發展歷程中,GPT 的主要轉折點在 GPT 3 上。因為在應用Transformer算法之前,人們無法看出它的潛力。正如之前提到的,OpenAI 跑出了賽道,因為他是第一家將具有智商 180 的天賦異稟的孩子訓練到了 1000 億級參數的 GPT 3,這是第一家做到的。因此,GPT 3 比其他人更快地達到了臨界點和爆發點,而其他人仍在訓練 GPT 2 級別的模型,仍在使用數十億級別的參數進行訓練。
GPT 3通過微調和遷移學習來利用少量的樣本進行學習。
GPT 4 已經在 OpenAI 上開始應用了,但目前僅限于付費用戶使用,因為 OpenAI 是一個閉源的平臺,它不公開使用了多少參數。但是大家基本上可以猜測,大概 GPT 3.5 的參數量達到了 1700 多億。GPT-4 在 3. 5 基礎上,規模擴大了 100 倍,應該是達到了萬億級別、十萬億級別的參數量。因此,它的能力非常強大,可以幫助你撰寫文章、進行新聞分析,甚至編寫 Python 代碼等等。
然而 GPT本身仍然存在缺陷和局限性。

大家看這張圖片是我隨意測試的結果。我測試了李白是否寫過一首古詩來贊美“鄭和下西洋”,而它很聰明地判斷出“鄭和下西洋”屬于明代,而李白是唐代的詩人。但是,當我再次欺騙它時,問它李白是否寫過一首有關“大禹治水”的詩,它就上當了,它真的寫了一首像模像樣的大禹治水的詩。
盡管GPT已經發展到3.5和4,看起來非常聰明,但它仍然有其局限性,即它沒有真正的理解能力和知識能力。真正的知識能力是指真正的推理判斷能力。作為人類個體,我們的強大之處在于我們自己的判斷力。沒有判斷力,我們就只是一個計算機。GPT似乎什么都懂,但它沒有判斷力,因此會產生幻覺,它不太可靠,會有一些推理偏見和錯誤。因此,在使用GPT時,需要注意它的局限性。
或許在將來,我們可以在所有的概率判斷之前先加一層推理邏輯判斷,這樣它可能會變得更好,但這個算法會更加復雜和麻煩。你必須首先讓它具備推理能力,而以前我們的生成神經網絡做的就是推理學,而現在的Transformer則是做簡單的概率預測。這兩個東西存在一些差別,你需要讓它先做推理,再做預測。
我今天的分享就到這里,謝謝大家。
