
眼動追蹤越發成為頭顯的標準配置,各家廠商都在積極探索精確、輕型、緊湊和高成本效益的眼動追蹤系統。早前映維網已經分享了一系列與所述主題相關的廠商發明,而美國專利商標局日前又公布了一份名為“Distributed sensor module for eye-tracking”的Meta專利申請。
對于眼動追蹤,其中一個挑戰是需要將功耗降到最低,從而優化可穿戴設備的形狀參數設計和續航能力。一種降低功耗的方法是利用機器學習來執行目標追蹤,但所述方式需要一個大型網絡,而這不可避免地會產生功耗,并且不能提供足夠精確的結果。
為了解決上述問題,Meta希望通過一個分布式設置來減少功耗,并提供足夠精確的結果。簡單來說,可以由頭顯搭載一個傳感器模塊,并由在與頭戴式設備分離的本地計算設備中實現一個中央模塊。然后,傳感器模塊來檢測來自下采樣圖像的特征,從而執行對象追蹤,而中央模塊可處理傳感器模塊的任何潛在請求/服務。
所述分布式傳感器模塊包括攝像頭、存儲單元、檢測單元和計算單元,并用于通過機器學習模型從下采樣的圖像中有效地檢測特定特征。以所述方式,傳感器模塊可以生成/計算特定于特征的圖像,無需過度讀取圖像中的片段并降低功耗。
在一個實施例中,攝像頭配置為捕捉描繪用戶眼睛的一個或多個用戶圖像,存儲單元配置為存儲圖像,檢測單元可以從下采樣版本的圖像中檢測包括用戶眼睛特征的一個或多個第一片段,并從存儲單元讀取與下采樣版本圖像中的第一片段相對應的一個或多個圖像中的一個或多個第二片段。然后,計算單元可以基于包括圖像中眼睛特征的第二片段來計算用戶的注視點,而不搜索原始圖像中每個片段中的特征(這需要額外的時間和能力來從原始圖像讀取/檢測每個片段)。因此,所述傳感器模塊可以在一定程度降低功耗。

圖1示出了具有bounding box110和分割遮罩120的圖像100。在特定實施例中,機器學習模型接受訓練以處理圖像(例如圖像100),并檢測圖像中的特定對象。在所述示例中,機器學習模型經過訓練以識別人的特征。在特定實施例中,機器學習模型可以輸出包圍檢測到的對象類型實例(例如人)的bounding box110。矩形bounding box可以表示為四個二維坐標,并表示框的四個角。在特定實施例中,機器學習模型可以附加地或可選地輸出識別屬于所檢測實例的特定像素的分割遮罩120。例如,分割遮罩120可以表示為二維矩陣,每個矩陣元素對應于圖像的像素,而元素的值對應于關聯像素是否屬于檢測目標。
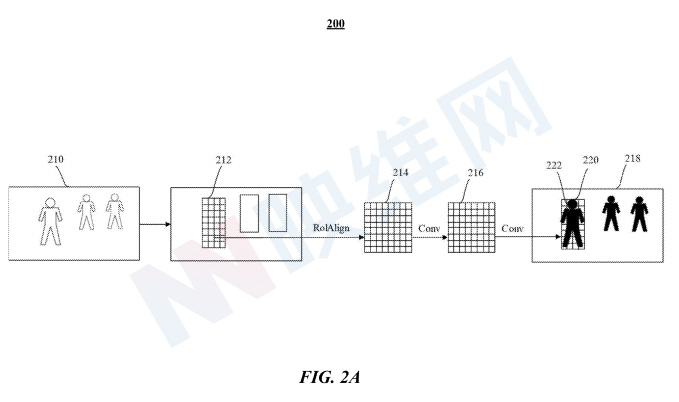
圖2A示出了機器學習模型200的架構。機器學習模型200配置為將圖像210或圖像的預處理表示作為輸入,例如三維矩陣,其尺寸對應于圖像的高度、寬度和顏色通道,比方說紅色、綠色和藍色。機器學習模型200識別包圍圖像210中的目標對象(例如人)的bounding box212。另外,機器學習模型200配置為讀取圖像210的下采樣版本(例如下采樣圖像218)中的bounding box220中的片段222,并檢測作為與圖像210中的bounding box212中的目標對象對應的目標區域(RoI)的區段222。在特定實施例中,RoI可包括人、汽車或任何其他類型的對象。
在一個實施例中,可以通過任何可操作的計算機視覺技術來檢測下采樣圖像218中的RoI。例如,包括RoIWarp for RoI pooling或RoaAign的Mask R-CNN可以處理圖像210以確定作為RoI的bounding box212,并通過使用ROAlign經由卷積層214、216將圖像210中的bounding box212映射到特征映射(例如下采樣圖像218中的bounding box220對應于圖像210中的bounding box212),將圖像210卷積到下采樣圖像218中,并在圖像210中輸出與bounding box212中的特征對應的分割遮罩。
在特定實施例中,機器學習模型200配置為輸出對象檢測(例如圍繞人的邊界框的坐標)、關鍵點(例如代表被檢測人的姿勢)和/或分割遮罩(例如識別對應于被檢測人的像素)。在特定實施例中,每個分割遮罩具有與輸入圖像(例如圖像210)相同數量的像素。在特定實施例中,分割遮罩中對應于目標對象的像素標記為“1”,其余像素則標記為“0”,以便當分割遮罩覆蓋在輸入圖像上時,機器學習模型200可以有效地選擇與捕獲圖像中的目標對象相對應的像素,例如包括圖像210中用戶特征的區段。
Meta指出,機器學習模型的200架構旨在降低復雜性,從而減少處理需求,以在資源有限的設備產生足夠精確和快速的結果,并滿足實時應用的需求,例如每秒10、15或30幀。與基于ResNet或Feature Pyramid Networks(FPN)的傳統架構相比,機器學習模型200要小得多,并且可以更快地生成預測,例如大約快100倍。
所以,這個機器學習模型可用于檢測關于用戶眼睛的特征(例如用戶眼睛的輪廓),以便實時計算用戶的注視點。
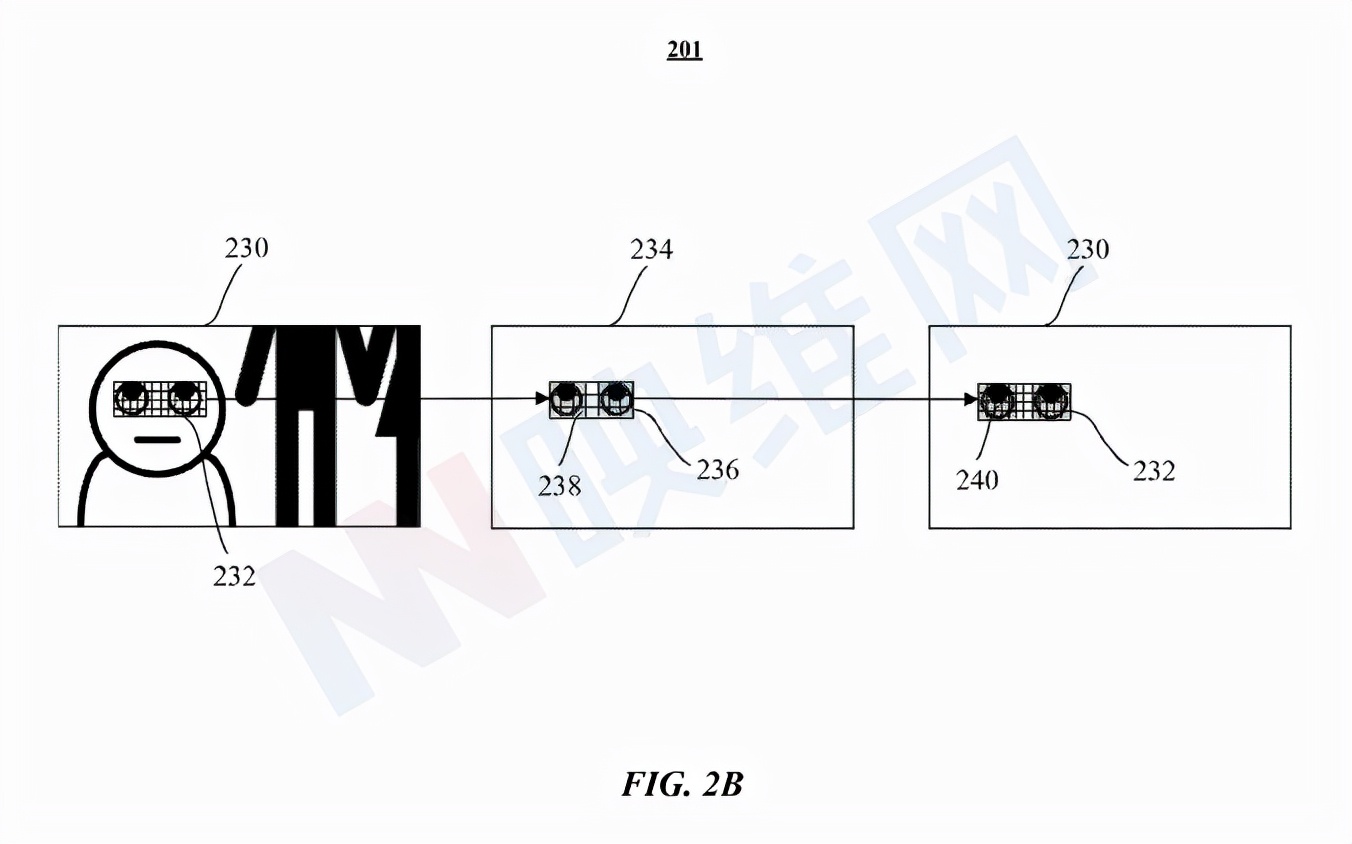
圖2B示出了用于預測bounding box、分段遮罩和關鍵點的機器學習模型201的示例架構。機器學習模型201配置為獲取輸入圖像230,并且通過處理圖像230的下采樣版本(例如下采樣圖像234),輸出N個區段236。其中,區段236是下采樣圖像234中的RoI。在特定實施例中,RoI是用戶的眼睛特征/關鍵點,例如,用戶眼睛的輪廓、虹膜的邊緣和/或用戶眼球中的反射。
在圖2B中,輸入圖像230包括包圍用戶眼睛特征并由一個或多個區段組成的bounding box232。機器學習模型201處理輸入圖像230的下采樣版本(例如下采樣圖像234),并讀取下采樣圖像234中對應于輸入圖像230中的bounding box232的bounding box236中的區段,以檢測包括目標眼睛特征的一個或多個第一區段238。因此,當需要計算用戶的注視點時,用機器學習模型201實現的追蹤系統可以直接讀取/檢索輸入圖像230中與在下采樣圖像234中用眼睛特征識別的第一區段238相對應的區段240。
在特定實施例中,輸入圖像230可存儲在存儲器或任何存儲設備中,這樣,可以簡單地從存儲器選擇性地讀取下采樣圖像234和描繪眼睛特征的全分辨率圖像的部分(例如下采樣圖像234的至少一部分),從而最小化消耗大量功率的存儲器訪問。
在特定實施例中,機器學習模型200、201可包括若干高級組件以檢測bounding box、關鍵點和分割掩碼。組件中的每一個都可以配置為神經網絡。從概念上講,機器學習模型200、201在所示架構中配置為處理輸入圖像并準備表示圖像的特征映射,例如卷積輸出的起始。RPN獲取由神經網絡生成的特征映射,并輸出N個可能包括感興趣對象的擬議RoI。
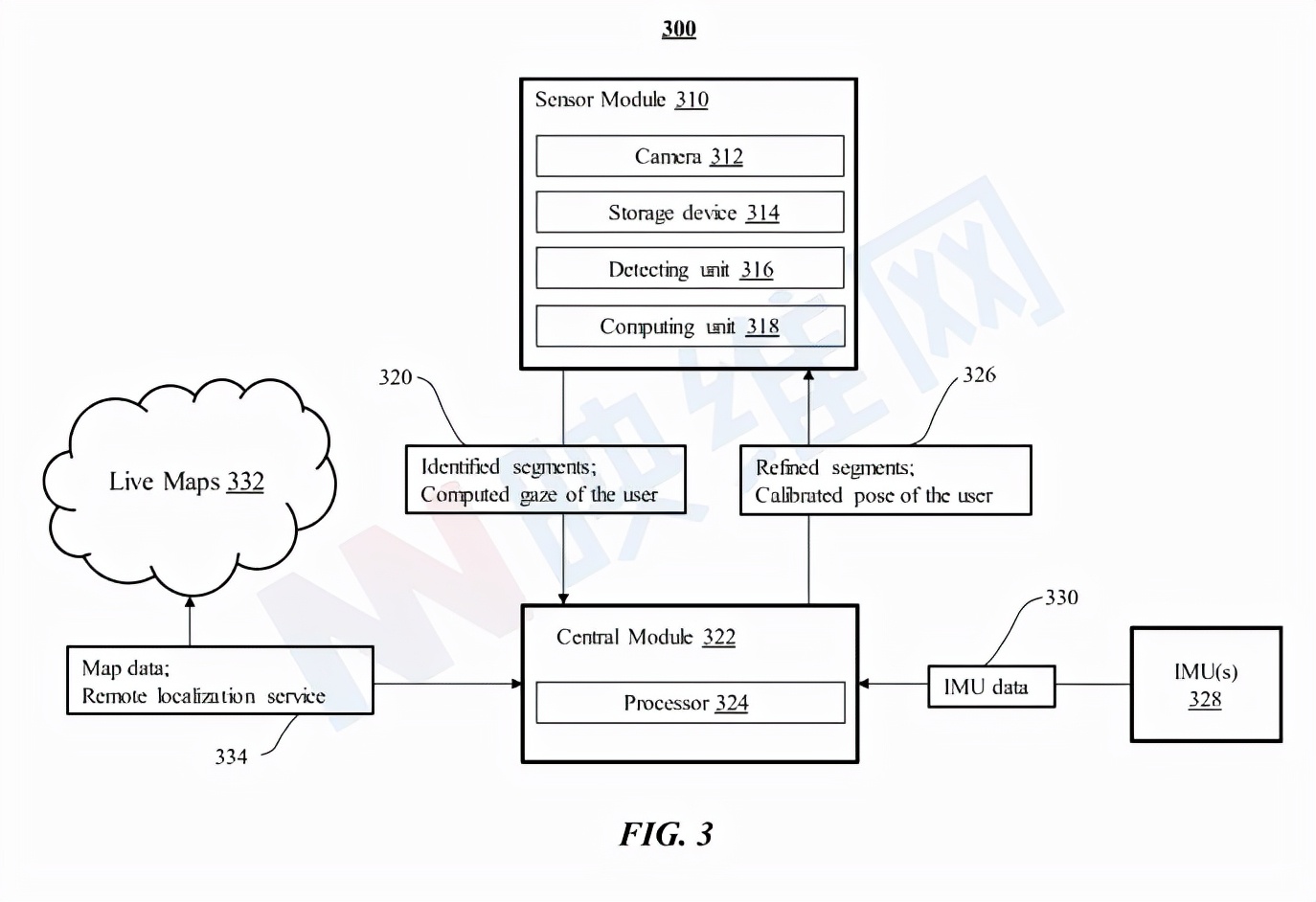
圖3示出了根據追蹤系統架構。追蹤系統300包括至少一個傳感器模塊310和中央模塊322。傳感器模塊310包括至少一個攝像頭312,其捕捉用戶的一個或多個圖像,而圖像可以是描繪用戶眼睛特征的用戶的一系列幀。傳感器模塊同時可以包括存儲用戶捕捉的圖像的存儲單元314和檢測單元316,后者利用機器學習模型來實現,以在捕獲圖像的下采樣版本中檢測包含用戶眼睛特征的區段。傳感器模塊同時包括計算單元318,其基于與捕獲圖像的下采樣版本中的檢測片段相對應的捕獲圖像中的片段來計算用戶的注視點。
另外,中央模塊322包括至少一個處理器324,處理器324進一步處理來自傳感器模塊310的捕獲圖像320中的用戶的計算注視點和識別片段。中央模塊進一步包括來自一個或多個IMU 328的慣性測量單元(IMU)數據330,所述慣性測量單元(IMU)數據330在帶有傳感器模塊310的頭戴式設備中實現。例如,中央模塊322基于所拍攝圖像的所識別片段中的特征,以及從IMU 328發送的IMU數據330中提供的camera姿勢、速度、加速度和運動來估計用戶的狀態,另外,中央模塊322可以利用用戶的狀態來細化捕獲圖像中的片段,并將用戶326的細化片段/注視點提供給傳感器模塊310。
在特定實施例中,中央模塊322可以為用戶320的計算注視執行廣泛的服務,以降低功耗,例如在本地或全局定位用戶/設備(例如遠程定位服務334)。在特定實施例中,中央模塊322處理來自IMU 328的IMU數據330,以提供用戶的預測姿勢并幫助生成用戶的狀態。在特定實施例中,如果需要,中央模塊322可以通過基于從傳感器模塊310發送的捕獲圖像320中的識別片段中的特征檢索實時映射332來定位傳感器模塊310。實時映射332包括用于用戶/傳感器模塊310的定位的映射數據334。中央模塊322可以校準用戶在映射數據334的姿勢,并將用戶326的校準姿勢提供給傳感器模塊310。在特定實施例中,中央模塊322可以包括存儲設備,其用于存儲捕獲的圖像和/或用戶的計算注視點,以減輕傳感器模塊310的重量。
在特定實施例中,傳感器模塊310可在頭戴式設備中實現,而中央模塊322可在與頭戴式設備分離的本地計算設備實現。如在兩部分系統中。頭戴式設備包括一個或多個處理器,配置為實現傳感器模塊310的攝像頭312、存儲設備314、檢測單元316和計算單元318。在一個實施例中,每個處理器被配置為分別實現攝像頭312、存儲設備314、檢測單元316和計算單元318。本地計算設備包括配置為執行中央模塊322的一個或多個處理器。
一種基于機器學習(ML)的輕型眼動追蹤系統可以分階段執行,以最小化功耗。執行眼動追蹤系統以對傳感器模塊捕獲的圖像進行下采樣,從下采樣圖像中識別目標片段(例如,基于眼睛輪廓),基于識別的片段加載高分辨率圖像的目標區域,以及基于高分辨率圖像(例如最初捕獲的圖像)的RoI中的反射/折射計算注視點。眼動追蹤系統僅檢索高分辨率圖像的RoI,所以可以減少內存訪問和功耗。
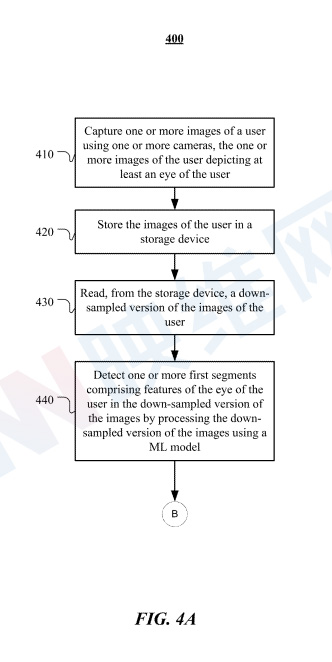
圖4A示出了傳感器模塊處檢測特征片段的示例方法400。方法400可以從步驟410開始:使用一個或多個攝像頭捕捉用戶的一個或多個圖像,用戶的一個或多個圖像描繪了用戶的至少一只眼睛。在特定實施例中,用戶的一個或多個圖像包括從一個或多個攝像頭的一個或多個視角捕獲的不同注視方向,從而確定用戶的注視點。
在步驟420,方法400可以將用戶的一個或多個圖像存儲在存儲單元中。在特定實施例中,存儲單元可以在具有一個或多個攝像頭的頭戴式設備中實現。
在步驟430,方法400可以從存儲設備讀取用戶的一個或多個圖像的下采樣版本。
在步驟440,方法400可以通過使用機器學習模型處理一個或多個圖像的下采樣版本,在一個或多個圖像的下采樣版本中檢測包含用戶眼睛特征的一個或多個第一區段。在特定實施例中,一個或多個第一區段包括用戶眼睛輪廓的至少一部分。
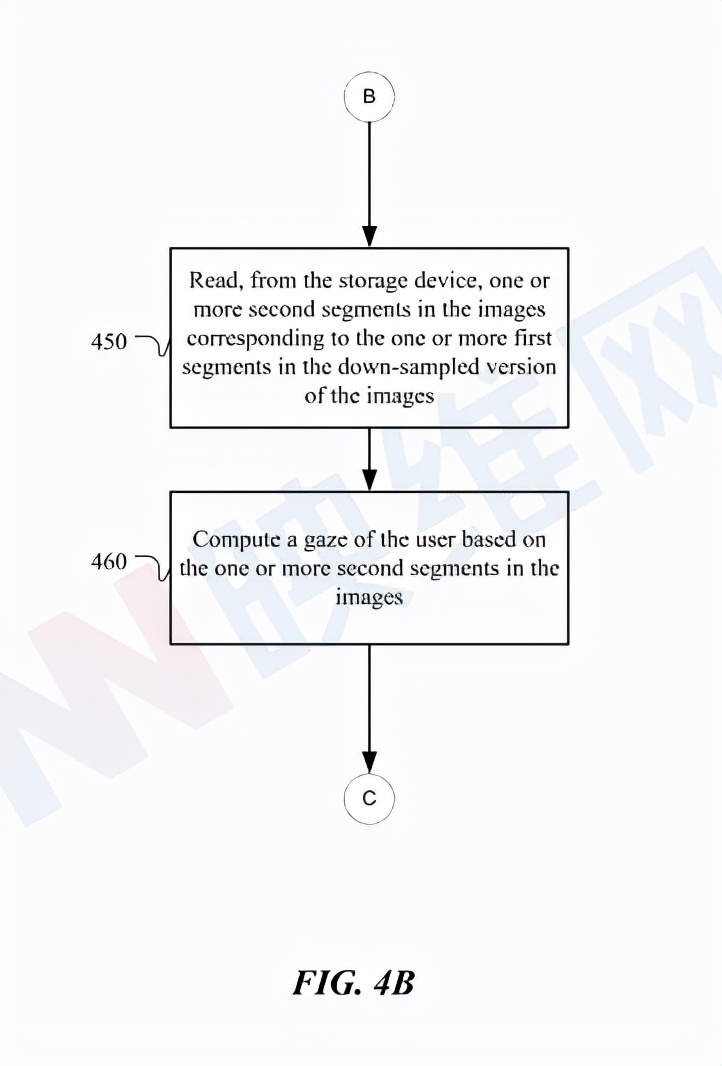
圖4B的示例方法401通過讀取與傳感器模塊處下采樣圖像中檢測到的區段相對應的圖像中的區段來計算用戶的注視點。方法401可以在方法400中的步驟440之后的步驟450開始:從存儲單元讀取與一個或多個圖像的下采樣版本中的一個或多個第一區段相對應的一個或多個圖像中的一個或多個第二區段。在特定實施例中,一個或多個第二區段包括用戶眼睛中的反射和/或折射。在特定實施例中,一個或多個第二區段包括至少一個注視方向。
在步驟460,方法401可以基于一個或多個圖像中的一個或多個第二區段來計算用戶的注視點。
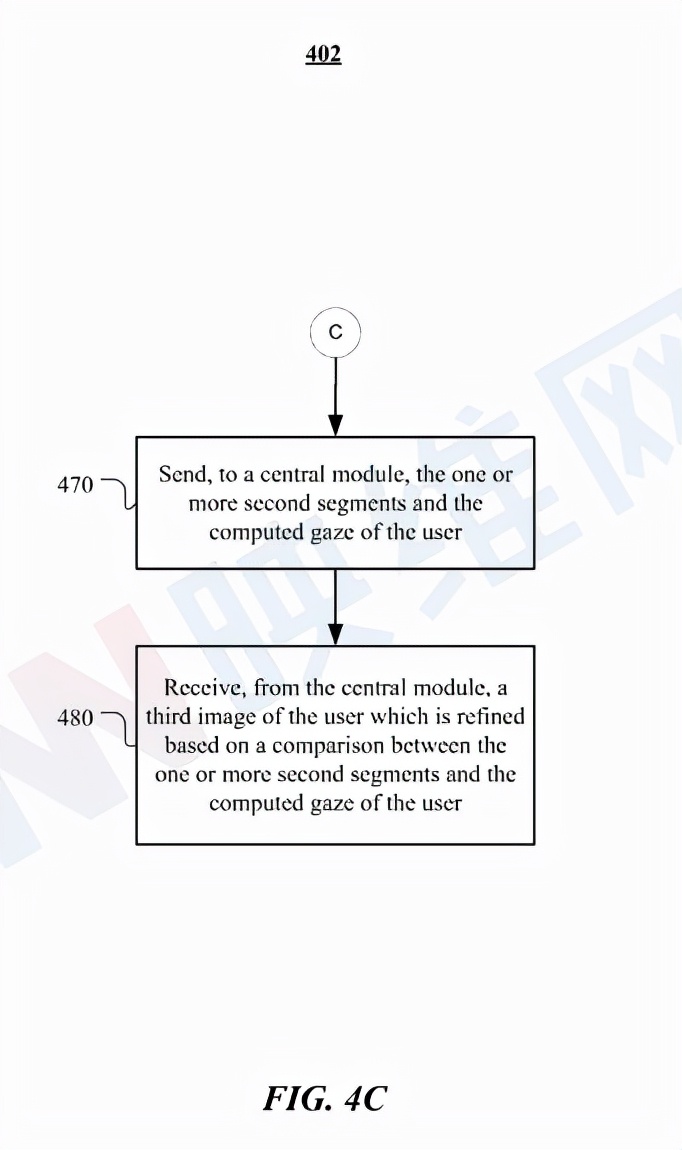
圖4C示出了在中央模塊處理的圖像細化示例方法402。在方法401中的步驟460之后的步驟470,方法402可以開始向中央模塊發送一個或多個第二區段和用戶的計算注視點。
在步驟480,方法402可以從中央模塊接收用戶的第三圖像,所述圖像基于一個或多個第二片段與用戶的計算注視點之間的比較而實現細化。在特定實施例中,中央模塊可以在與頭戴式設備分離的本地計算設備中實現。中央模塊可處理傳感器模塊的任何潛在請求/服務,以降低功耗。
相關專利:Facebook Patent | Distributed sensor module for eye-tracking
名為“Distributed sensor module for eye-tracking”的Meta專利申請最初在2020年8月提交,并在日前由美國專利商標局公布。
