
Meta AI開源的大羊駝LLaMA模型徹底點燃了開源社區的熱情,并在此基礎上相繼開發出了各種類ChatGPT的羊駝Alpaca, Vicuna等。
但Meta只是開源了LLaMA的權重,訓練用到的數據集并沒有開源出來,對于那些想從頭開始訓練LLaMA的從業者來說,目前還沒有開源方案。
最近,由Ontocord.AI,蘇黎世聯邦理工學院DS3Lab,斯坦福CRFM,斯坦福Hazy Research 和蒙特利爾學習算法研究所的宣布開啟「紅睡衣」(RedPajama)計劃,旨在生成可復現、完全開放、最先進的語言模型,即從零一直開源到ChatGPT!
下載地址:
https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T
預處理倉庫:https://github.com/togethercomputer/RedPajama-Data
「紅睡衣」開源計劃總共包括三部分:
1. 高質量、大規模、高覆蓋度的預訓練數據集;
2. 在預訓練數據集上訓練出的基礎模型;
3. 指令調優數據集和模型,比基本模型更安全、可靠。

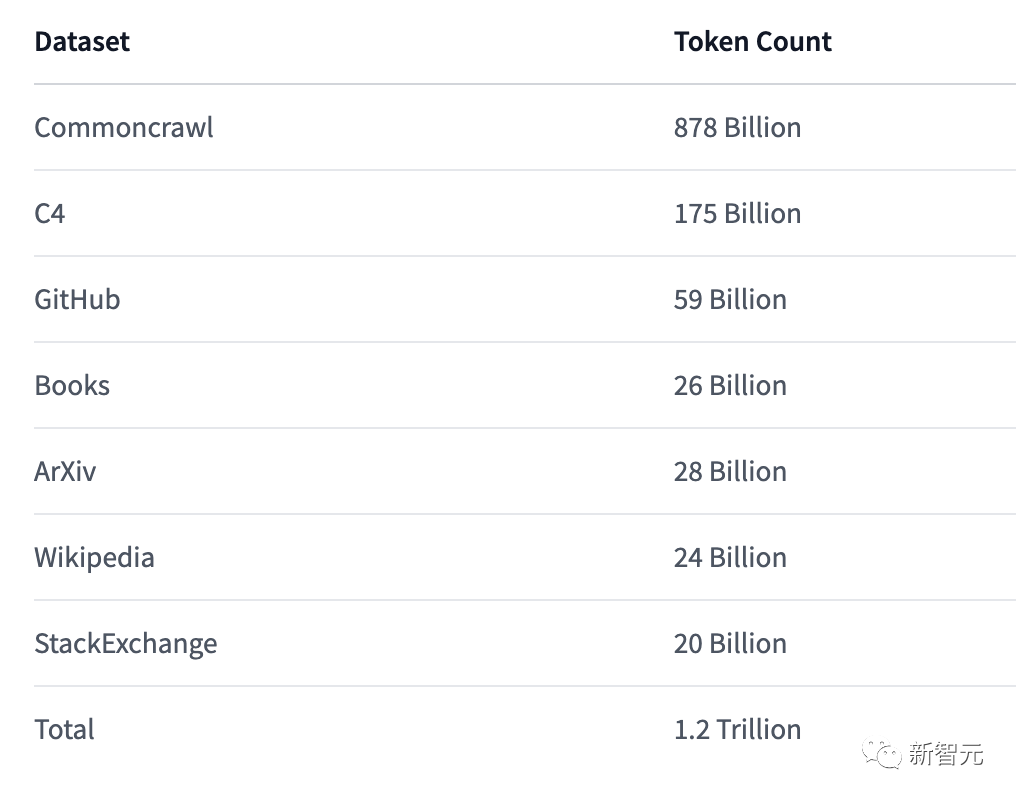
目前紅睡衣計劃中的第一部分,即預訓練數據集RedPajama-Data-1T已開源,包括七個子集,經過預處理后得到的token數量大致可以匹配Meta在原始LLaMA論文中報告的數量,并且數據預處理相關腳本也已開源。
完整的RedPajama-Data-1T數據集需要的存儲容量為壓縮后3TB,解壓后5TB,有條件、有網速的小伙伴可以開始搞起來了!
目前開發團隊正在橡樹嶺領導計算設施(OLCF)的支持下開始訓練模型,預計幾周后即可開源。
通過OpenChatKit,研究人員已經收到了數十萬條高質量的自然用戶指令,將用于發布 RedPajama 模型的指令優化版本。
復刻LLaMA
2023年2月27日,Meta推出LLaMa并發布了相關論文。

論文鏈接:https://arxiv.org/pdf/2302.13971.pdf
LLaMa實際上是一組基礎語言模型的統稱,其參數范圍從70億到650億不等,其中LLaMA-13B(130億參數)版本甚至在大多數基準測試中都優于1750億參數的GPT-3;最大的LLaMA-65B和Chinchilla-70B和PaLM-540B相比也不落下風。
和之前的大模型不同的是,LLaMa完全使用「公開數據集」就達到了SOTA,并不存在其他模型中「不可告人」的秘密,無需使用專用或只存在于虛空中的數據集。
具體使用的數據集和預處理操作如下。
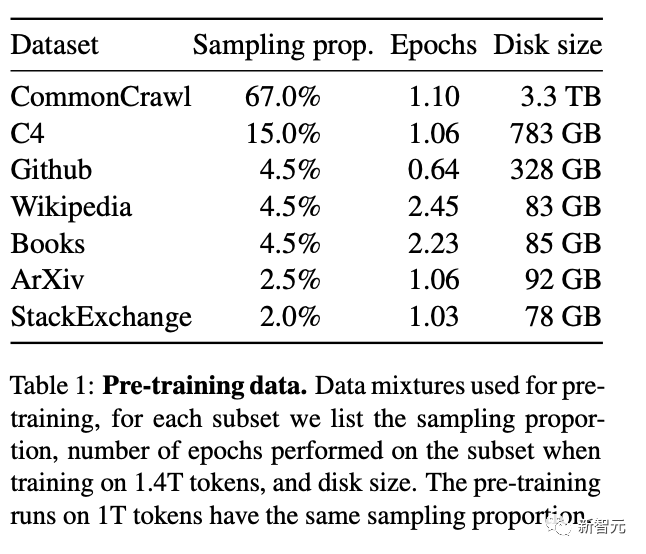
English CommonCrawl-占比67%
使用CCNet pipeline對五個CommonCrawl dumps(2017-2020年)進行預處理,刪除重復的行,并用fastText線性分類器進行語言分類,去除非英語頁面,并用ngram語言模型過濾低質量內容。
還訓練了一個線性模型來對維基百科中用作參考文獻的頁面與隨機采樣的頁面進行分類,并去除未被分類為參考文獻的頁面。
C4-占比15%
在探索實驗中,研究人員觀察到使用多樣化的預處理CommonCrawl數據集可以提高性能,所以將公開的C4數據集納入我們的數據。
C4的預處理也包含重復數據刪除和語言識別步驟:與CCNet的主要區別是質量過濾,主要依靠啟發式方法,如是否存在標點符號,以及網頁中的單詞和句子數量。
Github-占比4.5%
使用谷歌BigQuery上的GitHub公共數據集,只保留在Apache、BSD和MIT許可下發布的項目。
然后用基于行長或字母數字字符比例的啟發式方法過濾了低質量的文件,并用正則表達式刪除了HTML boilerplate(如等)。
最后在文件層面上對所生成的數據集進行重復計算,并進行精確匹配。
維基百科-占比4.5%
數據集中添加了2022年6月至8月期間的維基百科dumps,涵蓋20種語言,包括使用拉丁字母或西里爾字母的語言,具體為bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk;然后對數據進行預處理,以去除超鏈接、評論和其他格式化的html模板。
Gutenberg and Books3-占比4.5%
訓練數據集中包括兩個書籍相關的語料庫,Gutenberg Project為公共領域的書籍;ThePile中Books3部分是一個用于訓練大型語言模型的公開數據集。
預處理操作主要是刪除重復內容超過90%的書籍。
ArXiv-占比2.5%
通過處理arXiv的Latex文件將科學數據添加到訓練數據集中,刪除了第一節之前的所有內容,以及書目;還刪除了.tex文件中的注釋,以及用戶寫的內聯擴展的定義和宏,以提高不同論文的一致性。
Stack Exchange-占比2%
Stack Exchange是一個高質量問題和答案的網站,涵蓋了從計算機科學到化學等不同領域。保留了28個最大網站的數據,刪除了文本中的HTML標簽,并按分數(從高到低)對答案進行了排序。
分詞器(Tokenizer)
根據SentencePiece的實現使用字節對編碼(byte-pair-encoding,BPE)算法對數據進行分詞,其中連續的數字被分割成單個數字。
最終整個訓練數據集在分詞后獲得了大約1.4T的tokens,除了維基百科和圖書數據外,其他的數據在訓練期間只使用一次,總共進行了約兩個epochs。
參考資料:https://www.together.xyz/blog/redpajama
