

圖片來源:視覺中國
大模型面向產(chǎn)業(yè)落地的難點是什么?
1.當下,基于生成式的人工智能技術(shù)(AIGC),仍然需要海量數(shù)據(jù)進行訓練才能得到一個回復質(zhì)量較高的模型算法,初期訓練成本非常之高。這對于傾向自研基礎(chǔ)大模型的企業(yè)是必須要過的門檻。
2.對于給出算法更加精準、訓練成本更低、對于用戶調(diào)取更方便的模型,這一方面的提升空間較為明晰。在媒體、游戲、營銷等行業(yè)已經(jīng)看到比較多典型的內(nèi)容生成場景,但AIGC技術(shù)并不能適用于所有場景,且在商業(yè)層面的實際回報率尚未明朗。
3.從市場需求的共性來看,企業(yè)對AI技術(shù)更關(guān)心,關(guān)心怎么跟業(yè)務融合,但同時也會有些擔憂或緊張,新技術(shù)會不會對業(yè)務帶來沖擊。與此同時,各國對人工智能和數(shù)據(jù)獲取監(jiān)管的法律條文,以及對“類ChatGPT”的支持力度,也在反映這種觀望態(tài)度。
過去半年,整個科技圈有關(guān)AIGC創(chuàng)新的新聞鋪天蓋地,但一頓操作猛如虎之后,還有更多仍在“來的路上”。
6月1日,阿里云宣布通義大模型進展,聚焦音視頻AI的“通義聽悟”正式亮相,成為國內(nèi)首個開放公測的大模型應用產(chǎn)品。
通義聽悟其前身是早在2021年研發(fā)投入市場的“聽悟”產(chǎn)品,此次除了集成阿里通義千問大模型的理解與摘要能力外,還融合了阿里最先進的語音語義、多模態(tài)算法等技術(shù)。公測期間,聽悟用戶可通過每日登陸等多種任務領(lǐng)取免費轉(zhuǎn)寫時長,阿里云官方多個平臺也會放大量20小時的轉(zhuǎn)寫口令碼。除此之外,聽悟企業(yè)版還在與釘釘“釘閃記”、夸克APP、阿里云盤等進行能力進行集成。
此舉對于國內(nèi)的AI語音技術(shù)服務商以及“類ChatGPT”應用企業(yè),并不是個好消息。
從聽悟到通義聽悟
結(jié)合當前的官方定義來看,通義聽悟具備“聽”與“悟”能力,即“聽力好”,能高準確度生成會議記錄、區(qū)分不同發(fā)言人,“悟性高”,可形成摘要、總結(jié)全文及每個發(fā)言人觀點、整理關(guān)注重點和待辦事項。
這其實也明確了外界對AI音視頻技術(shù)產(chǎn)品的一個重要期待:要讓AI理解人類,并且以人類可理解的方式表達出來。AI理解人類,意味著不只要聽到表面語義,甚至還要理解人的情緒和意圖;AI表達,則意味著在文本生成、內(nèi)容摘要、風格及情緒表達上要有所突破。同時結(jié)合多模態(tài)技術(shù),不只是文字、音頻,還有圖像、視頻等方式傳遞給AI理解。
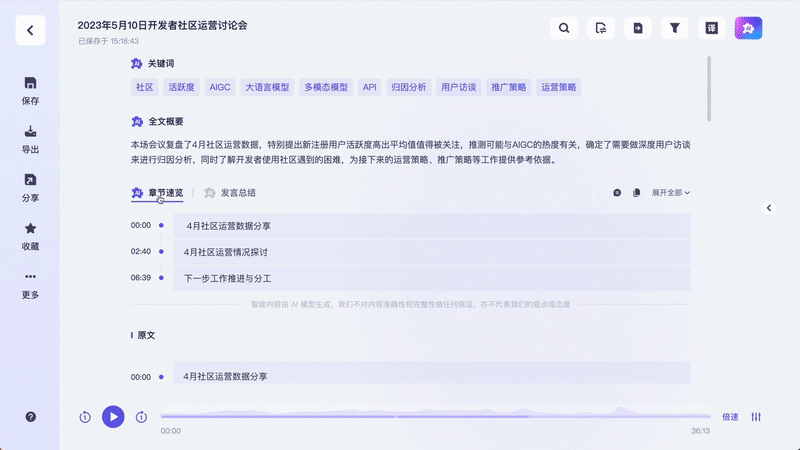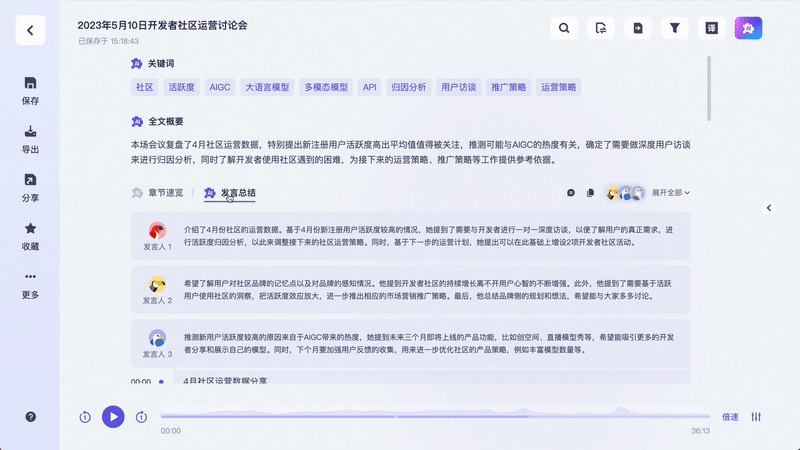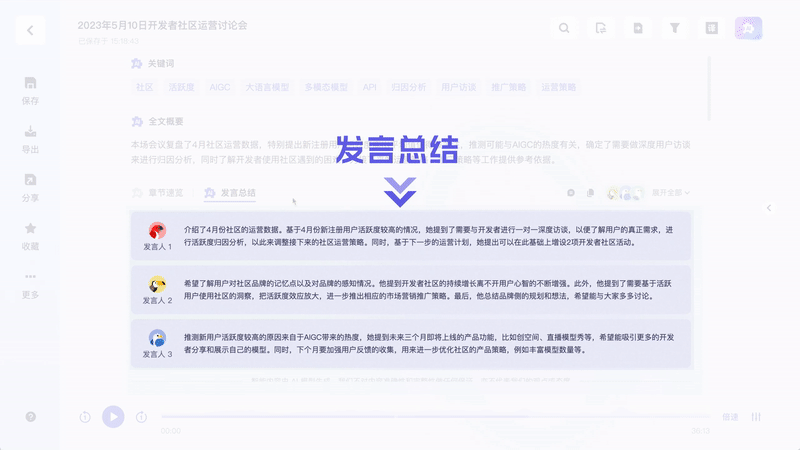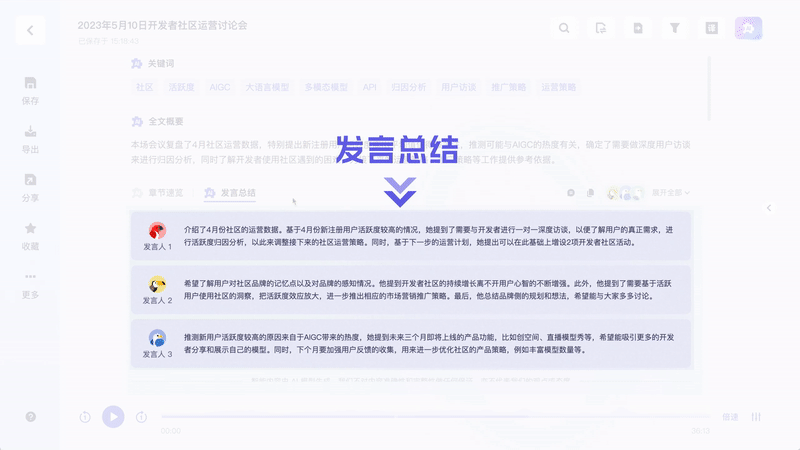
這個過程,在沒有大模型技術(shù)應用前,就已經(jīng)存在諸多細節(jié)性挑戰(zhàn)。但在阿里云CTO周靖人看來,有了通義大模型的加持,阿里將多年積累的語音技術(shù),以及多模態(tài)的能力有機結(jié)合起來,最終形成今天的通義聽悟。
“‘知其然不知所以然’是產(chǎn)品沒有大模型的局限性,過去的聽悟只能做到將語音文字轉(zhuǎn)錄出來,但背后的整理、理解、信息收取,是依靠人來完成的。之前也曾用過小模型,但結(jié)果并不好。”周靖人在會后的交流活動中指出。
以語音識別TTS為例,聽悟內(nèi)置了語音識別模型Paraformer,它首次在工業(yè)級應用層面解決了端到端識別效果與效率兼顧的難題。配合GPU推理,不同版本的Paraformer可將推理效率提升5~10倍,同時,Paraformer使用了6倍下采樣的低幀率建模方案,可將計算量降低近6倍,支持大模型的高效推理。
說話人識別模型CAM++,相較于如ECAPA-TDNN和ResNet模型,在準確識別和高效計算的同時,還實現(xiàn)了整體優(yōu)解。在行業(yè)主流的中英文測試集VoxCeleb和CN-Celeb上均刷新了最優(yōu)準確率,并且在計算效率和推理速度上有著明顯優(yōu)勢。
而此次聽悟上線測試的通義千問大模型的信息摘要能力,為保證抽取出的摘要信息的事實準確,大幅度減少幻覺,團隊還融合了在推理、對齊和對話問答等方面的研究成果。如在推理能力方面,2022年團隊提出了基于大語言模型的知識探測與推理利用的框架 Proton。
對手會是訊飛嗎?
業(yè)內(nèi)普遍一個聲音是,“很多產(chǎn)品因為大模型的到來會重新再做一遍”,接入大模型能力,或?qū)⒏淖兊氖钱a(chǎn)品的業(yè)務邏輯、交互模式,甚至是收費模式。
從通義聽悟當前的產(chǎn)品界面上看,針對的仍然是比較高頻的場景,往往跟對話或交流相關(guān),如上述提及的總結(jié)、翻譯、內(nèi)容摘取,其本質(zhì)上是對內(nèi)容語義的理解輸出。據(jù)官方描述,其定位為一款工作學習AI助手,瞄準具有高知識附加值的音視頻內(nèi)容場景,如開會、上課、訪談、培訓、面試、直播、看視頻、聽播客等,能通過大模型等最新AI技術(shù)快速提煉和沉淀知識。
通義聽悟的技術(shù)負責人鄢志杰一直都在從事智能語音交互相關(guān)工作,他解釋道,“目前展示的視頻轉(zhuǎn)文字,仍然是將視頻里的音頻進行文字轉(zhuǎn)換,尚未展示出視頻直接轉(zhuǎn)文字的理解過程。未來會進行多模態(tài)的理解,不僅要有音頻轉(zhuǎn)文字,還要輔助以視頻和視覺的模態(tài)對內(nèi)容進行更好的理解。”
下一步,通義聽悟會被各種各樣的業(yè)務系統(tǒng)集成,集成到智能化服務中,開發(fā)者可根據(jù)實際場景,最終打造基于業(yè)務場景的MaaS服務,“通義聽悟一定會推出企業(yè)版,為企業(yè)場景所定制,每個企業(yè)也都會有不同的需求,也有數(shù)據(jù)安全、數(shù)據(jù)隱私等方面的要求。”周靖人補充道。
那么,通義聽悟的對手會是訊飛嗎?
事實上,音視頻是人機交互的重要入口,市面上成熟的AI音視頻產(chǎn)品并不在少數(shù),除了訊飛、搜狗、網(wǎng)易有道等具備軟硬件能力的服務商外,飛書妙記、騰訊會議等互聯(lián)網(wǎng)公司孵化的企業(yè)辦公生產(chǎn)力工具,也同樣具備相似的能力。可能的區(qū)別在于,背后的AI技術(shù)邏輯,是否會因大模型的到來而徹底改變。
科大訊飛于上月發(fā)布星火大模型,其中軟件產(chǎn)品訊飛聽見會寫已經(jīng)搭載大模型開放使用,在收費模式上已經(jīng)給市場參考標準——根據(jù)單次AI能力的使用(單次字數(shù)不超過8000字)按月/季/年會員收費。
互聯(lián)網(wǎng)公司在這方面的積累也從未缺席,在不斷豐富AI技術(shù)體系的同時,也在迅速推進大模型+的創(chuàng)新。例如從早期的iDST實驗室到達摩院,阿里2019年開始投入大模型,2021年訓練實現(xiàn)10萬億參數(shù)的多模態(tài)大模型M6,2022年發(fā)布通義大模型,到如今的通義千問、通義聽悟已經(jīng)在逐步產(chǎn)業(yè)化融合。
《中國人工智能大模型地圖研究報告》指出,據(jù)不完全統(tǒng)計,中國10億級參數(shù)規(guī)模以上大模型已發(fā)布了79個,特別是在自然語言理解、機器視覺、多模態(tài)等方面,出現(xiàn)了多個在行業(yè)有影響力的大模型。上述提及的網(wǎng)易有道則基于教育場景推出了“子曰”大模型,出門問問的“序列猴子”則面向多模態(tài)生成能力的大語言模型……
可見,能容納后來者的賽道,依然存在尚未挖掘的價值空間,更何況大模型將帶來新的變量。
