
7 月 25 日消息,近來諸多國產大模型異軍突起,助力相關行業產業發展。北京知未智能科技有限公司日前在上海發布了知未智能 KDF 大模型 ,以及基于該模型研發的一系列產品,包括“ KDF 智訊”、“KDF 絕未”、“KDF 中書”等金融行業工具。
知未智能 KDF 大模型的訓練數據以中文為主,并包含大量的金融數據,以提升模型在商業和金融領域的問題處理能力。
此外,訓練數據中還融合了部分英文與代碼數據,以適應模型的通用能力。在訓練過程中,知未智能 KDF 大模型將單個漢字視為獨立的 Token 進行處理。模型參數量達 1400 億,訓練 Token 數達到 4000 億。從代碼量角度看,數據處理部分約 5000 行,模型實驗部分約 2000 行,模型訓練部分約 500 行。
在具體訓練過程中,知未智能 KDF 大模型采用了基于 PyTorch 優化的 GELU 非線性激活函數。GELU 作為非線性激活函數,在各類任務中表現相對出色,有助于模型更精確地捕獲復雜數據特征,確保整個開發、訓練和部署過程的高效運行。
在網絡結構方面,開發團隊對模型進行了深度優化。與 LLaMA 模型相比,該模型在每一層使用更少的參數,有效降低計算需求和內存占用。同時,網絡深度得到加強,使模型具備更強大的表示能力,能夠學習到更為復雜的數據特征。
為提升模型在大規模數據處理中的可擴展性,開發團隊重新調整了注意力層的 Bias,并引入了 Flash Attention 技術,旨在節省顯存并提高模型訓練和推理速度。得益于降低的計算量和內存需求,Flash Attention 使得知未智能 KDF 大模型在有限的硬件資源下實現更高效的運行。
從部分基準測試結果來看,知未智能 KDF 大模型在七個自然語言處理任務中展現出穩定的性能。在某些任務上,如 iFlytek 和 CMNLI,知未智能 KDF 大模型表現相對出色,在 ExamQA 和 OCNLI 測試中,各模型的表現大致相同,凸顯了該模型處理不同類型文本和領域知識方面的能力。
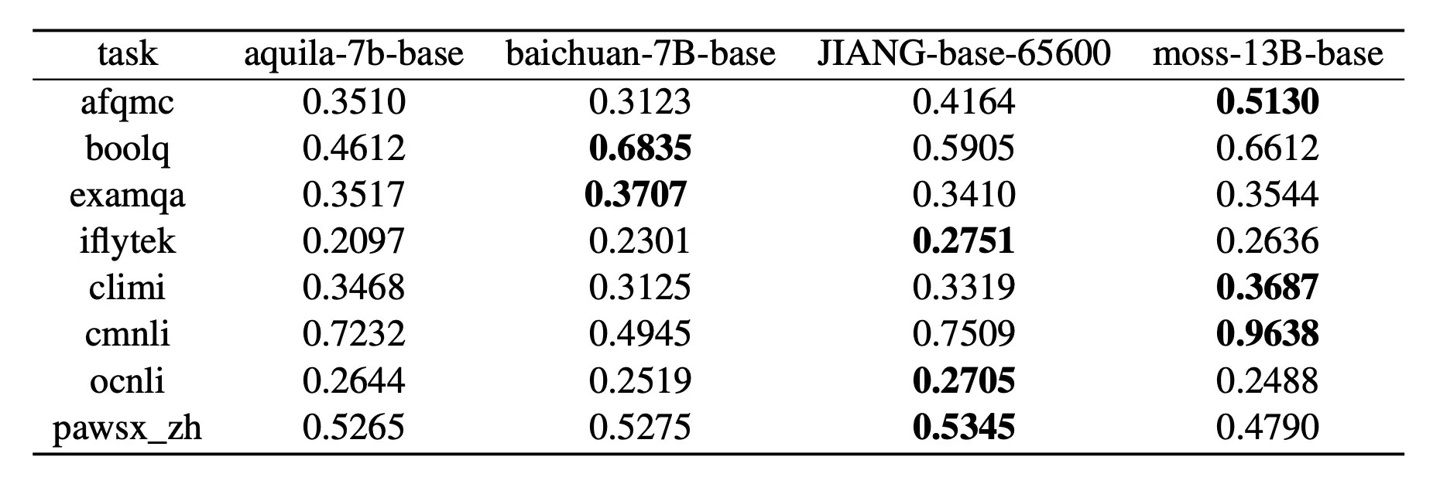
▲ 圖源 Hugging Face
知未智能科技 CEO 段清華表示,現有通用大模型在具體行業應用性和中文能力方面的局限是知未智能選擇從零訓練知未智能 KDF 大模型的主要原因,Chatglm 在具體行業應用能力上相對薄弱,MOSS 采用英文模型為基底而對中文支持不足,LLaMA 訓練數據大多為英文數據而中文能力相對較弱。因此研發團隊選擇從零開始訓練知未智能 KDF 大模型,以便更好地提升其中文能力以及行業適用性。
在模型訓練過程中,開發團隊不斷深入理解技術細節,力求打造一款“功能強大、性能優越”的中文模型,作為一款應用于金融和商業的垂直領域大模型,知未智能 KDF 大模型將持續推動公司產品的開發創新。
知未智能 KDF 大模型目前已于 Hugging Face 開源,未來將不限制商業使用,感興趣的小伙伴們可以在此進行了解。
