
作者|李晗 朱悅
編輯|栗子
妙鴨相機火了。
無需高額的價格、無需耗時的定妝,只需要9.9元和20張個人照片,就可以利用AI生成媲美“海馬體”“天真藍”的精美照片。
憑借低廉的價格和較好的生成效果,“妙鴨相機”一經推出便迅速出圈。
不過,這次出圈的不止是產品,還有當時近似“霸王條款”的用戶協議。
據媒體報道,妙鴨相機初版用戶協議的“授權許可”條款頗具爭議。一句話就是:用戶授權妙鴨相機,無償且永久地使用該信息。

圖片來源:網絡
“這樣操作,其實是國內無數軟件、APP的默認選項,但是正大光明地說出來,可以說‘有恃無恐’了。”某互聯網數據信息安全企業負責人向「甲子光年」表示。
面對用戶的質疑,妙鴨相機很快修改了相關條例,并在官方公眾號、小紅書等多個平臺發布了道歉聲明,直言:已經收到用戶關于用戶協議的反饋,原協議內容有誤,已第一時間根據妙鴨的實際情況進行了修改。“在這里鄭重地向大家承諾,您所上傳的照片只會用于數字分身制作,不會提取也不會用于識別和其他用途,且分身制作完成后自動刪除。”
事實上,一直以來,“互聯網服務與數據安全難以兩全”都是一個棘手的問題。妙鴨相機用戶協議授權問題,僅僅是互聯網數據安全問題的一個縮影。
長期專注于數據合規領域,曾為多家境內外上市公司、知名企業提供數據合規服務的北京植德律師事務所合伙人王藝告訴「甲子光年」:“目前有較多因為‘AI換臉’軟件產生的侵權案件,利用AI技術侵犯個人隱私數據的案例數量也在逐步上升。”
用戶處于被動位置,難以保障自身的數據安全, 隱私保護的無力感正在從互聯網時期蔓延至AI時代。但顯而易見的是,在AI時代,企業對數據的爭奪更加激烈,用戶數據隱私安全面臨的挑戰也更加嚴峻。
大模型訓練不僅離不開豐富的數據集,也愈加需要高質量的數據;由于涉及到人與AI的交互,用戶的個人信息權利難以響應,技術開發者、服務提供者也面臨著潛在的合規風險。
當老生常談的問題遇上新的技術變革,大模型時代又將打響怎樣的數據安全保衛戰?
在創新與安全的平衡中,法律規范、企業自治、數據安全技術正在給出它們的答案。
1.大模型時代,數據安全的新挑戰
數據,是AI發展的養料。人們在輕而易舉獲取數據的同時,對數據安全的討論也此起彼伏。
2013年,線上辭典Dictionary.com將“Privacy(隱私)”選為當年的年度詞匯。彼時美國政府棱鏡計劃被曝光、谷歌修改隱私協議以整合旗下各服務用戶數據,個人隱私成為數據安全中關注度最高、涉及人群最廣的方面。
相較于互聯網對用戶上網習慣、消費記錄等信息的覆蓋,人臉識別、智能設備、AI換臉等AI應用的出現,對用戶個人信息的采集范圍大幅擴大,包括人臉、指紋、聲紋、虹膜、心跳、基因等強個人屬性的生物特征信息。
2017年,中國第一例利用AI侵犯公民個人信息案犯罪在浙江紹興破獲,其中超10億條公民個人信息被非法獲取。
360集團首席安全官杜躍進此前接受「甲子光年」采訪時就曾表示:“人工智能和大數據的安全必須放在一起看。”
生成式AI、大模型的出現,對數據提出了前所未有的要求,也隨之帶來了更加突出的數據安全問題。
在大模型的訓練數據量上,以OpenAI的GPT模型為例:GPT-1預訓練數據量僅為5GB;到了GPT-2,數據量已經增加至40GB;而GPT-3的數據量已經直接飛升至45TB(相當于GPT-2數據量的1152倍)。
市場逐漸凝成這樣的共識:得數據者得天下,數據是大模型競爭的關鍵。
頂象安全專家告訴「甲子光年」:“模型需要數據來訓練。數據除了自己采集,就是爬蟲爬取。爬取的數據大部分沒有經過數據所有者允許,可以說大部分是非授權的盜用。”
2022年11月,OpenAI和GitHub一起推出的代碼助手Copilot就曾被程序員們告上法庭。原告們認為,Copilot在未獲得GitHub用戶授權的情況下,使用了公共存儲庫進行訓練。
在今年6月,OpenAI同樣因為未經允許使用個人隱私數據收到了一份長達157頁的訴訟書。
除了模型的訓練階段,在模型的實際應用階段中,個人隱私泄露的風險持續存在。
頂象安全專家告訴「甲子光年」,生成式AI不僅僅泄露人的隱私和秘密,甚至會讓人變得透明。“就跟《三體》中的智子一樣,提問者說的話會被記錄下來,生產生活產生的數據信息會成為AIGC訓練的素材。”
早在2020年,人們就發現OpenAI的GPT-2會透露訓練數據中的個人信息。隨后的調查發現,語言模型越大,隱私信息泄露的概率也越高。
今年3月,多名ChatGPT用戶在自己的歷史對話中看到了他人的對話記錄,包括用戶姓名、電子郵件地址、付款地址、信用卡號后四位以及信用卡有效期。
不到一個月之后,三星電子就因員工使用ChatGPT,被迫面臨三起數據泄露事故:其半導體設備測量、良品/缺陷率、內部會議內容等相關信息被上傳到了ChatGPT的服務器中。隨后,三星立即禁止員工在公司設備及內網上使用類ChatGPT的聊天機器人,同樣禁用的公司還包括蘋果、亞馬遜、高盛等世界500強公司。
觀韜中茂律師事務所發布的《生成式AI發展與監管白皮書(三)》解釋了大模型在應用上的特殊性。大模型與人之間的交互,不同于一般應用程序中填入式的收集個人信息方式,所以對于個人信息的披露也不同于往常意義上的“公開披露”,更類似于一種“被動公開”,即當某個用戶的真實個人信息被摘錄在語料庫后,之后任意用戶通過詢問等方式均可以得知相關個人信息。
這意味著,在大模型時代,不僅個人信息泄露的范圍擴大了,個人信息的采集過程也變得更為隱秘,難以辨認,而且一旦侵權,就是對大量用戶造成的侵權。那么,泄露之后的個人信息去向了哪里?究竟會對用戶造成什么影響?
北京植德律師事務所合伙人王藝告訴了「甲子光年」答案。他表示,生成式AI造成的個人信息泄露,輕則可能侵害他人的肖像權,為造謠者實施便利,重則可能被犯罪分子利用,實施犯罪。
頂象的安全專家也表示,在所有互聯網產品或軟件都有可能被植入AI元素的當下,AI濫用帶來的社會問題會越來越多。“造假會更簡單,眼見不一定為實,電信詐騙、網絡詐騙越來越復雜。”
2023年5月,安全技術公司邁克菲對來自七個國家的7054人進行了調查,發現有四分之一的成年人經歷過某種形式的AI語音詐騙(10%發生在自己身上,15%發生在他們認識的人身上),10%的受害者因此造成經濟損失。
「甲子光年」從慧科數據庫、公開報道中發現,今年以來全國各地發現利用AI技術竊取個人隱私進行詐騙的案例至少有14例。
其中,大多數案例通過視頻聊天與受害者進行聯系,逼真的人臉和聲音容易讓人們放下警惕,冒充朋友、親人也迅速讓受害者交與信任。詐騙金額多在萬元以上,最高被詐騙金額甚至高達430萬元。
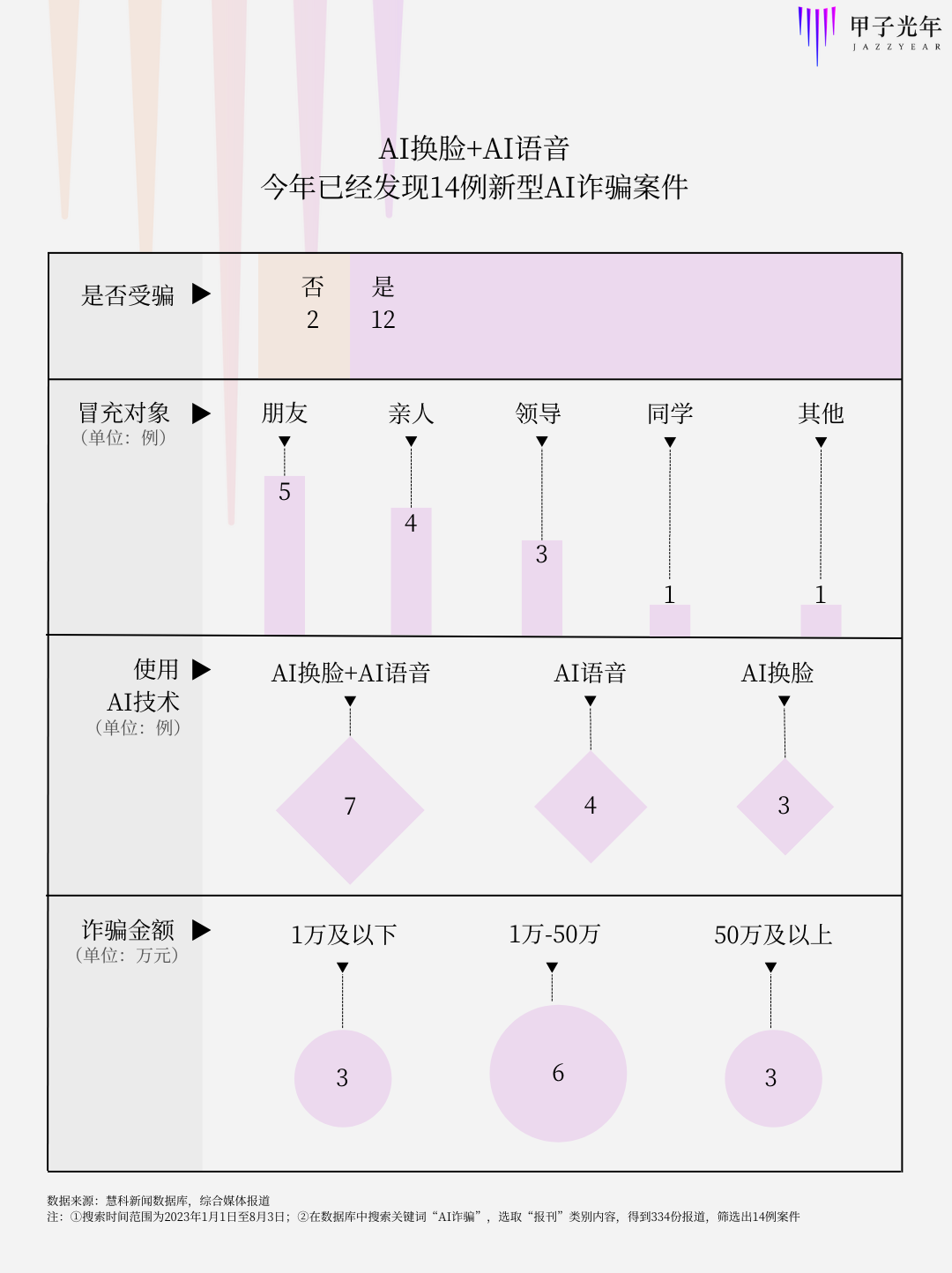
數據來源:慧科新聞數據庫,綜合媒體報道
除此之外,通過“AI換臉”造成肖像權被侵犯的案件也屢見不鮮。王藝表示,雖然此類案件的數量在逐步上升,但由于隱蔽性強,且是微型侵權,很多案例都沒有走上法庭,即使進行了法院審判,得到的賠償金額也并不高。
可以說,普通人在面對利用AI技術進行的個人隱私侵權面前,其實并沒有太多的辦法。
2.嚴苛的立法態度不是監管的唯一解法
技術發展與法律監管總是并駕齊驅的。如果說數據安全已經成為人工智能時代的必答題,法律與監管便是解答的關鍵。
今年4月,斯坦福大學以人為本人工智能研究所(Stanford HAI)發布了《2023年人工智能指數報告》(Artificial Intelligence Index Report 2023)報告。通過對127個國家的立法記錄調研,報告顯示,包含“人工智能”法案通過的數量,從2016年的1個增長到2022年的37個。在對81個國家涉及人工智能的議會記錄進行分析后,研究人員發現全球立法程序中提及人工智能的次數自2016年以來增加了近6.5倍。
區別于信息剽竊、隱私侵犯等“老生常談”的數據安全問題,由于涉及到人與AI的交互,大模型時代數據安全面臨著更為迫切的難題——個人信息權利響應難以落實。
如何精準識別交互過程中收集的個人信息?如何劃清用戶服務與模型訓練的使用界限?面對全新的數據安全、個人信息安全、網絡安全難題,大模型時代亟須新的監管辦法出臺。
2023年7月13日,中國網信辦發布《生成式人工智能服務管理暫行辦法》(下文簡稱《暫行辦法》,2023年8月15日施行),明確規定了生成式人工智能服務提供者的服務規范。
在涉及個人信息安全的相關條例中,《暫行辦法》規定:
第九條 提供者應當依法承擔網絡信息內容生產者責任,履行網絡信息安全義務。涉及個人信息的,依法承擔個人信息處理者責任,履行個人信息保護義務。
提供者應當與注冊其服務的生成式人工智能服務使用者(以下稱使用者)簽訂服務協議,明確雙方權利義務。
第十一條 提供者對使用者的輸入信息和使用記錄應當依法履行保護義務,不得收集非必要個人信息,不得非法留存能夠識別使用者身份的輸入信息和使用記錄,不得非法向他人提供使用者的輸入信息和使用記錄。
提供者應當依法及時受理和處理個人關于查閱、復制、更正、補充、刪除其個人信息等的請求。
隨著管理細則逐步落實、施行日期臨近,多家服務提供商也在開展自檢自查。據了解,由于數據采集和使用環節不夠規范,蘋果應用商店已經下架了多款AIGC相關軟件。數據規范的緊迫性可見一斑。
除了數據安全外,對技術的監管不可避免地涉及“發展與監管”之間的矛盾。北京植德律師事務所合伙人王藝告訴「甲子光年」:“如何處理二者之間的矛盾,是不同國家的戰略選擇。”
相較于4月11日發布的《生成式人工智能服務管理辦法(征求意見稿)》(下文簡稱《征求意見稿》),《暫行辦法》做出了較大改動。
《暫行辦法》刪除了對研發主體的監管要求,將《征求意見稿》中將強制性的“生成內容應當真實準確”修改為非強制性的“提高生成內容的準確性和可靠性”,并補充要求提升生成式人工智能服務的透明度。
“監管部門對《征求意見稿》的很多條款進行了刪除或者松綁。從立法前后稿子的變化,可以看出我國還是以發展為先的。”王藝說道。
在監管和發展平衡中,此次條例的修改不無道理。因為立法監管并非是一蹴而就的,過于嚴苛的立法態度可能會成為技術發展的掣肘。在歐洲,部分技術從業者就該問題表達了擔憂。
ChatGPT推出后,歐洲國家對OpenAI的監管逐步加緊。意大利宣布禁用ChatGPT后,出于數據保護的考慮,德國、法國、西班牙等國家也表示正在考慮對AI聊天機器人采取更嚴格的監管。
6月14日,歐盟通過的《人工智能法案》最新草案,也貫徹了以往嚴苛的立法態度。法案對于“基礎模型”或經過大量數據訓練的強大AI系統,明確規定了透明度和風險評估要求,包括在AI技術投入日常使用之前進行風險評估等。
對風險的猜想是否高于實際?歐盟嚴苛的立法態度招致了歐洲風投公司和科技公司的許多不滿。
6月30日,歐洲各地的主要科技公司創始人、首席執行官、風險投資家等150家企業高管共同簽署了一封致歐盟委員會的公開信,警告歐盟法律草案中對人工智能的過度監管。
“想要將生成式人工智能的監管納入法律并以嚴格的合規邏輯進行,這種方法是官僚主義的,因為它無法有效地實現其目的。在我們對真正的風險、商業模式或生成人工智能的應用知之甚少的情況下,歐洲法律應該僅限于以基于風險的方法闡述廣泛的原則。”公開信中指出,該立法草案將危及歐洲的競爭力和技術主權,而無法有效解決我們現在和未來可能要面臨的挑戰。
無獨有偶,日本一名官員此前也表示,日本更傾向于采用比歐盟更寬松的規則來管理AI,因為日本希望利用該技術促進經濟增長,并使其成為先進芯片的領導者。
“一項新技術從研發到進入市場,再到融入社會生產、生活,產生風險是難以避免的,不能因為風險而放棄新技術的研發和應用。理想目標應是把風險最小化,把技術獲利最大化。”頂象的安全專家告訴「甲子光年」。
上述受訪者繼續說道,歐盟在規范AI問題上下手早,但其過度監管也限制了相關市場的發展,造成歐盟數字產業的發展速度落后于全球。在全球技術主權激烈競爭的背景下,立法與監管政策需要保持謹慎思考,在治理與發展之間做好平衡,在方便企業抵御AI倫理風險的同時,為企業、行業以及相關產業提供充分的發展空間。
“不發展是最大的不安全。”嚴苛的立法態度不是監管政策的唯一解法,企業和立法者也不應該是矛盾雙方,而是謀求數據安全與技術發展的同路人。
以美國為例,谷歌、微軟、OpenAI等科技巨頭也在主動構建安全屏障。7月21日,谷歌、微軟、OpenAI、Meta在內的7家AI公司參與白宮峰會,并就AI技術和研發的安全、透明、風險等問題作出“八大承諾”。7月26日,微軟、谷歌、OpenAI、Anthropic四家AI科技巨頭宣布成立行業組織——“前沿模型論壇”(Frontier Model Forum),來確保前沿AI開發的安全和負責。
8月3日,我國網信辦發布關于《個人信息保護合規審計管理辦法(征求意見稿)》也進一步細化落實了《個人信息保護法》中個人信息處理者合規審計的相關要求,進一步完善了我國個人信息處理者自我規制。
面對尚未確定的技術生態,技術開發者、服務提供者都面臨著潛在的合規風險。只有明確了合法獲取的路徑和規章底線,大模型訓練者、服務提供者才能放下戒備,在更大的空間施展拳腳。
站在技術變革的十字路口,如何平衡好數據安全與技術發展的需求,制定出更為系統、更具針對性的監管細則,也是對各國立法者的新考驗。
3.在創新與安全之間,如何平衡?
“監管,如果不向前邁進,就會面臨人工智能被濫用的風險;如果倉促行事,就有導致行業陷入困境的危機。”
7月25日,Anthropic聯合創始人兼CEO Dario Amodei、加州大學伯克利分校教授Stuart Russell和蒙特利爾大學教授Yoshua Bengio出席美國參議院司法委員會舉行的人工智能聽證會。在會議上,他們一致達成這樣的觀點:AI需要監管,但過猶不及。
面對大模型對隱私數據的挑戰,在創新與安全的博弈之間,我們還有哪些解法?
加強數據安全保護可能是最容易想到的答案。360集團首席安全官杜躍進此前接受「甲子光年」采訪時曾表示:“數據安全不應該關注采集了什么,而應該關注采集的數據是怎么用的,怎么保護的。”
隱私計算成為近些年數據隱私保護的技術最優解。與傳統的加密技術相比,隱私計算可以在不泄露原始數據的前提下對數據進行分析計算,實現數據的共享、互通、計算和建模。
讓數據變得“可用不可見”,也就規避了個人數據泄露或不當使用的風險。這項技術目前已經在醫療、金融、政府等對數據高度敏感的領域內相繼落地。
在大模型時代,隱私計算也同樣適用。中國信通院云計算與大數據研究所副主任閆樹在7月的兩次活動上都表達了這樣的觀點,隱私計算可以滿足大模型預測階段的隱私保護需求。
具體來說,隱私計算的不同路線,包括可信執行環境(TEE) 、多方安全計算(MPC)等都可以與大模型進行結合,“比如在云端部署TEE ,用戶在推理時將輸入數據加密傳輸至云端,在其內部解密然后進行推理;還有在模型推理階段使用多方安全計算來提升隱私保護能力”。但值得注意的是,隱私計算也不可避免會對模型訓練和推理的性能造成影響。
除了加強數據安全保護之外,還有一種可以從數據源頭上解決隱私安全問題的方法——合成數據。
合成數據指通過AI技術和算法模型,基于真實數據樣本生成虛擬數據,因此也不存在用戶的個人隱私信息。
隨著大模型的火熱,合成數據也越來越受到關注,保護隱私就是合成數據研究背后強有力的驅動力之一。
“合成數據解決了三個挑戰——質量、數量和隱私。”合成數據平臺Synthesis AI的創始人兼CEO Yashar Behzadi接受科技媒體《VentureBeat》采訪時表示:“通過使用合成數據,公司可以明確定義所需要的訓練數據集,可以在最大程度上減少數據偏差并確保包容性,不會侵犯用戶的隱私。”
OpenAI聯合創始人兼CEO Sam Altman同樣也看好合成數據。
根據英國《金融時報》報道,5月在倫敦舉行的一次活動上,Sam Altman被問及是否擔心監管部門對ChatGPT潛在隱私侵犯的調查,他并沒有特別在意,而是認為“非常有信心所有的數據很快會成為合成數據”。
在合成數據方面,微軟在今年更是動作頻頻。5月,微軟在論文《TinyStories: How Small Can Language Models Be and Still Speak Coherent English?》中描述了一個由GPT-4生成的短篇小說合成數據集TinyStories,其中只包含了四歲兒童可以理解的單詞,用它來訓練簡單的大語言模型,也能夠生成出流暢且語法正確的故事。
6月,微軟在發布的論文《Textbooks Are All You Need》中論證,AI可以使用合成的Python代碼進行訓練,并且這些代碼在編程任務上表現得相當不錯。
在AI的圈子內,通過合成數據進行大模型的訓練早已見怪不怪。全球IT研究與咨詢機構Gartner預測,2030年,合成數據的體量將遠超真實數據,成為AI研究的主要數據來源。
在技術之外,數據市場也在漸漸明朗。北京植德律師事務所合伙人王藝向「甲子光年」介紹,目前已經有數據交易所建立了語料庫專區,并為相關語料數據產品掛牌(包括文本、音頻、圖像等多模態,覆蓋金融、交通運輸和醫療等領域),方便技術提供者和服務提供者合作采購。
在王藝看來,大模型數據的合法合規,需要生成式AI服務提供者首先做好數據分類分級,區分不同數據類型,如個人數據、商業數據、重要數據等,并根據這些不同數據的使用方式,找到對應的法律,分別開展數據來源合法性的審查工作。
而在監管方面,為了平衡好數據安全和AI的發展,王藝表示,對AI的監管需要有主次之分:重點在應用層的監管,尤其是內容監管和個人信息安全;其次是基礎層和模型層的監管,對于相關深度合成算法要督促其及時完成備案;再次是要關注技術本身的主體是否涉及境外,可能會存在數據出境、出口管制等問題。
每一次技術產生變革的時期,期待和恐懼總是如影隨形,發展和監管的呼聲向來不相上下。
目前大模型的發展還在早期,應用層的爆發尚未實現,但AI不會停下腳步,如何把控前行的方向,如何平衡安全與創新,或許是AI發展歷程中持續伴隨的命題。
(封面圖由Midjourney生成)
