

編譯 | 凌敏、核子可樂
自去年年底通過 ChatGPT 驚艷全球以來,OpenAI 一直保持著驚人的產品發布速度,通過迅如閃電的“組合拳”保持該公司在 AI 領域建立的統治地位與領導者形象。
但其他科技巨頭絕不可能坐視 OpenAI 一家獨大。谷歌已經公布大語言模型 Gemini,計劃于今年秋季首次與廣大用戶見面,且有報道稱該模型已經在接受指定企業客戶的測試。從目前的情況看,谷歌有可能后來居上、實現反超。
面對挑戰,OpenAI 連續放大招,除了發布新指令語言模型 GPT-3.5-turbo-instruct,還計劃推出多模態大模型 GPT-Vision 與 Gobi。據一位未公開身份的知情人士透露,OpenAI 在積極將多模態功能(類似于 Gemini 將要提供的功能)納入 GPT-4。
新語言模型 InstructGPT-3.5
近日,OpenAI 推出 GPT-3.5-turbo-instruct,這是一款新的指令語言模型,效率可以與聊天優化的 GPT-3.5 Turbo 模型相媲美。
指令模型屬于大語言模型的一種,會在使用一大量數據進行預訓練之后,再通過人類反饋(RLHF)做進一步完善。在此過程中,會由人類負責評估模型根據用戶提示詞生成的輸出,對結果做改進以達成目標效果,再將更新后的素材用于進一步訓練。
因此,指令模型能夠更好地理解并響應人類的查詢預期,減少錯誤并緩解有害內容的傳播。從 OpenAI 的測試結果來看,盡管體量僅為后者的百分之一,但人們明顯更喜歡擁有 13 億參數的 InstructGPT 模型,而非擁有 1750 億參數的 GPT 模型。
據了解,GPT-3.5-turbo-instruct 的成本與性能同其他具有 4K 上下文窗口的 GPT-3.5 模型相同,使用的訓練數據截止于 2021 年 9 月。

GPT-3.5-turbo-instruct 將取代一系列現有 Instruct 模型,外加 text-ada-001、text-babbage-001
和 text-curie-001。這三款 text-davinci 模型將于 2024 年 1 月 4 日正式停用。
OpenAI 表示,GPT-3.5-turbo-instruct 的訓練方式與之前的其他 Instruct 模型類似。該公司并未提供新 Instruct 模型的細節或基準,而是參考了 2022 年 1 月發布的 InstructGPT,即 GPT-3.5 模型的實現基礎。
OpenAI 稱,GPT-4 擁有超越 GPT-3.5 的復雜指令遵循能力,生成的結果也比 GPT-3.5 質量更高;但 GPT-3.5 也有自己的獨特優勢,例如速度更快且運行成本更低。GPT-3.5-turbo-instruct 并非聊天模型,這一點與原始 GPT-3.5 有所區別。具體來講,與之前的聊天應用模型不同,GPT-3.5-turbo-instruct 主要針對直接問答或文本補全進行優化。
速度方面,OpenAI 稱 GPT-3.5-turbo-instruct 速度與 GPT-3.5-turbo 基本相當。
下圖為 OpenAI 設計的 Instruct 指令模型與 Chat 聊天模型之間的區別。這種固有差異自然會對提示詞的具體編寫產生影響。
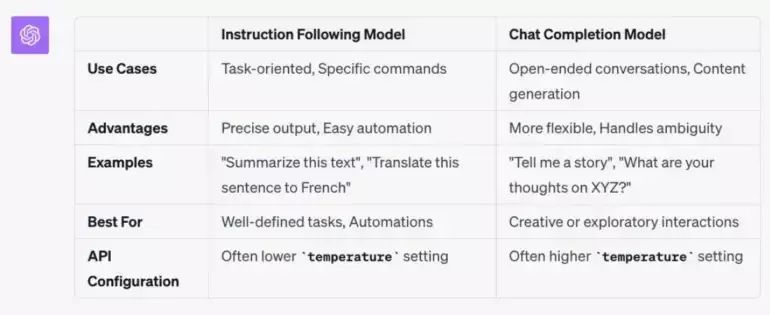
OpenAI 負責開發者關系的 Logan Kilpatrick 稱,這套新的指令模型屬于向 GPT-3.5-turbo
遷移當中的過渡性產物。他表示其并不屬于“長期解決方案”。已經在使用微調模型的用戶,需要根據新的模型版本做重新微調。目前微調功能只適用于
GPT-3.5,GPT-4 的微調選項計劃于今年晚些時候發布。
多模態大模型GPT-Vision 與 Gobi
除了 GPT-3.5-turbo-instruct,OpenAI 近日還計劃發布多模態大模型 GPT-Vision,以及一個代號為“Gobi”的更強大的多模態大模型。
據悉,GPT-Vision 在 3 月份的 GPT-4 發布期間首次預覽,是 OpenAI 融合文本和視覺領域的雄心勃勃的嘗試。雖然該功能最初實際用例僅限于 Be My Eyes 公司,這家公司通過其移動應用幫助視力障礙或失明用戶進行日常活動。
GPT-Vision 有潛力重新定義創意內容生成的界限。想象一下使用簡單的文本提示生成獨特的藝術品、徽標或模因。或者考慮一下對有視覺障礙的用戶的好處,他們可以通過自然語言查詢與視覺內容交互并理解視覺內容。該技術還有望徹底改變視覺學習和教育,使用戶能夠通過視覺示例學習新概念。
如今,OpenAI 正準備將這項名為 GPT-Vision 的功能開放給更廣泛的市場受眾。
此外,據 The Information 報道,OpenAI 即將發布代號為“Gobi”的下一代多模態大語言模型,希望借此擊敗谷歌并繼續保持市場領先地位。目前,Gobi 的訓練還沒有開始,有評論認為其有機會成為 GPT-5。
報道稱,OpenAI 之所以耗費大量時間來推出 Gobi,主要是擔心新的視覺功能會被壞人利用,例如通過自動解決驗證碼來冒充人類,或者通過人臉識別追蹤人們。但現在,OpenAI 的工程師們似乎想到辦法來緩解這個安全問題了。
OpenAI CEO:GPT-5 尚未出現,計劃將多模態功能納入 GPT-4
據了解,多模態大語言模型的本質是一種先進 AI 系統,能夠理解和處理多種數據形式,包括文本和圖像。與主要處理文本內容的傳統語言模型不同,多模態大語言模型能夠同時對文本加視覺類內容進行分析和生成。
也就是說,這類模型可以解釋圖像、理解上下文并生成包含文本和視覺輸入的響應結果。多模態大模型還擁有極高的通用性,適用于從自然語言理解到圖像解釋的諸多應用,借此提供更廣泛的信息處理能力。
報道指出,“這些模型能夠處理圖像和文本,例如通過查看用戶繪制的網站外觀草圖來生成網站構建代碼,或者根據文本分析結果輸出可視化圖表。如此一來,普通用戶也能快速理解內容含義,不必再向擁有技術背景的工程師們求助。”
OpenAI 首席執行官 Sam Altman 在最近的采訪中表示,盡管 GPT-5 尚未出現,但他們正計劃對 GPT-4 進行各種增強。而開放多模態支持功能,也許就是這項計劃的一部分。
在上周接受《連線》采訪時,谷歌 CEO 桑達爾·皮查伊表達了他對于谷歌當前 AI 江湖地位的信心,強調其仍掌握著技術領先優勢、并在創新與責任方面求取平衡的審慎戰略。他也對 OpenAI ChatGPT 的深遠意義表示認可,稱贊其擁有良好的產品 - 市場契合度、讓用戶對 AI 技術做好了準備。但他同時強調,谷歌在產品信任和負責態度方面會采取更加謹慎的立場。
參考鏈接:
https://the-decoder.com/openai-releases-new-language-model-instructgpt-3-5/
https://www.theinformation.com/articles/openai-hustles-to-beat-google-to-launch-multimodal-llm
https://aibeat.co/openai-multimodal-llm-gpt-vision-google/
